
Deep Learning
Derin Öğrenme
MLP RNN CNN
Veri
Tablo Karışık (Ses, Resim…) Resim
Tekrarlı Bağlantılar
Hayır Evet Hayır
Parametre Paylaşımı
Hayır Evet Evet
Mekânsal İlişki
Hayır Hayır Evet
Kaybolan & Patlayan
Gradyan
Evet Evet Evet
Deep Learning

Convolutional Neural Network
Evrişimsel Sinir Ağları
31 75
2 4 6 8
Giriş
Veri
Setleri
aramak
Problem
Alanı
Bilgisayarın
Ne Yapmasını
İstiyoruz?
Yapı
Test
yapmak
Girdiler
ve
Çıktılar
Biyolojik
Bağlantı
Eğitim
Şirketler
CNN’leri Nasıl
Kullanıyor?
GİRİŞ
Evrişimli sinir ağları. Küçük bir Bilgisayar Bilimlerinin serpiştirildiği biyoloji ve matematiğin
garip bir birleşimi gibi görünüyor, ancak bu ağlar bilgisayar vizyonu alanında en etkili
yeniliklerden birkaçıydı.
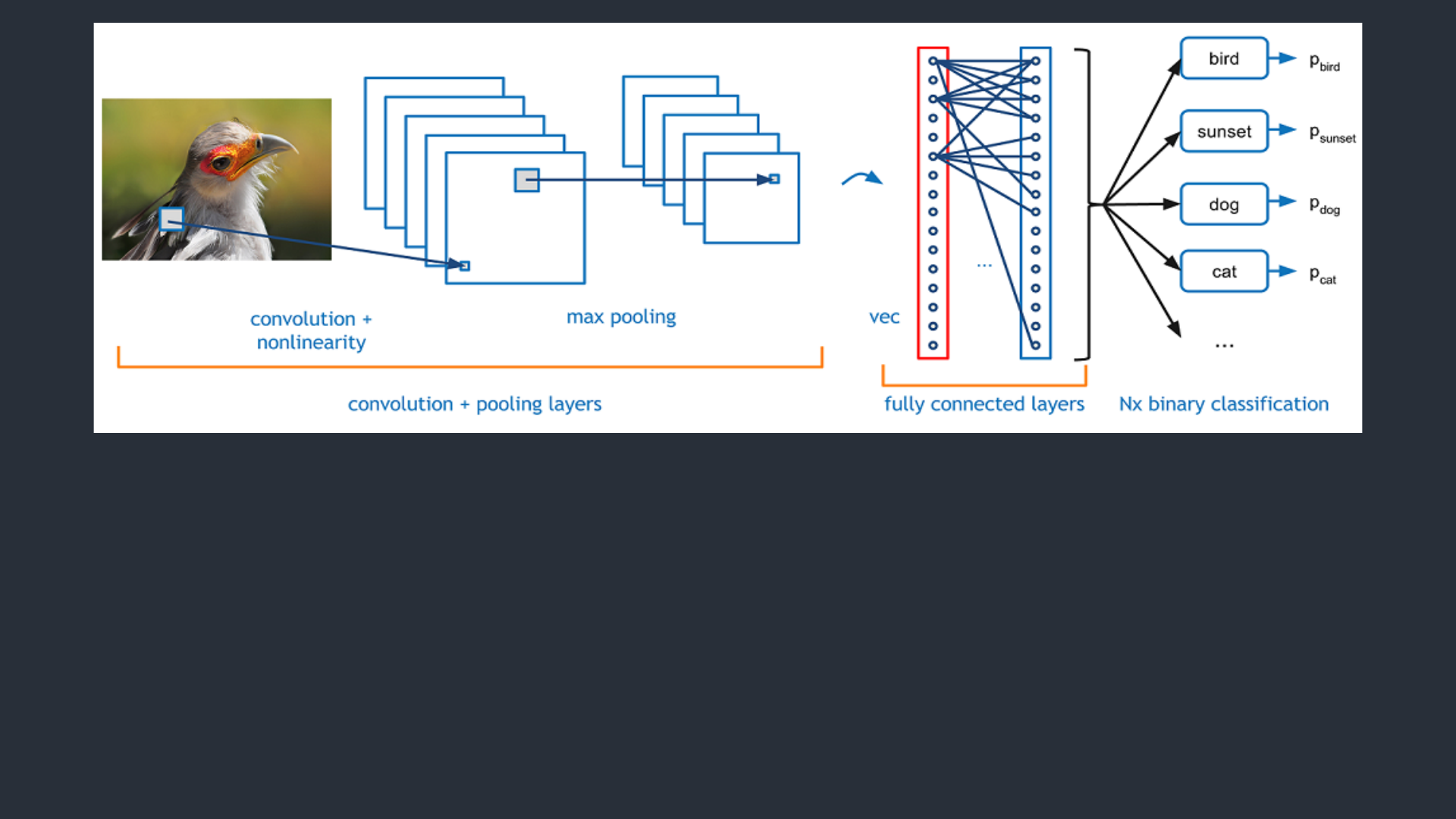
Bu ağların klasik ve tartışmasız en popüler, kullanım durumu görüntü işleme içindir. Görüntü
işleme dahilinde, görüntü sınıflandırması için bu CNN’lerin nasıl kullanılacağına bakalım.

Görüntü sınıflandırması, bir giriş görüntüsünün alınması ve bir sınıfın (bir kedi,
köpek, vb.) çıktısı veya görüntüyü en iyi tanımlayan sınıfların olasılığıdır. İnsanlar
için, bu tanıma görevi, doğduğumuz andan itibaren öğrendiğimiz ilk becerilerden
biridir ve yetişkinler olarak doğal ve zahmetsizce gelen özelliklerden biridir. İki kez
bile düşünmeden, içinde bulunduğumuz ortamı ve bizi çevreleyen nesneleri hızlı ve
sorunsuz bir şekilde tanımlayabiliriz. Bir görüntü gördüğümüzde ya da
etrafımızdaki dünyaya baktığımızda, çoğu zaman sahneyi hemen karakterize
edebiliyor ve her nesneye bilinçli olarak fark etmeden bir etiket verebiliyoruz.
Kalıpları hızlı bir şekilde tanıyabilmenin, önceden bilgiden genelleme yapmanın ve
farklı görüntü ortamlarına uyum sağlamanın bu yetenekleri, diğer makinelerimizle
paylaşmadığımız özelliklerdir.
Problem Alanı
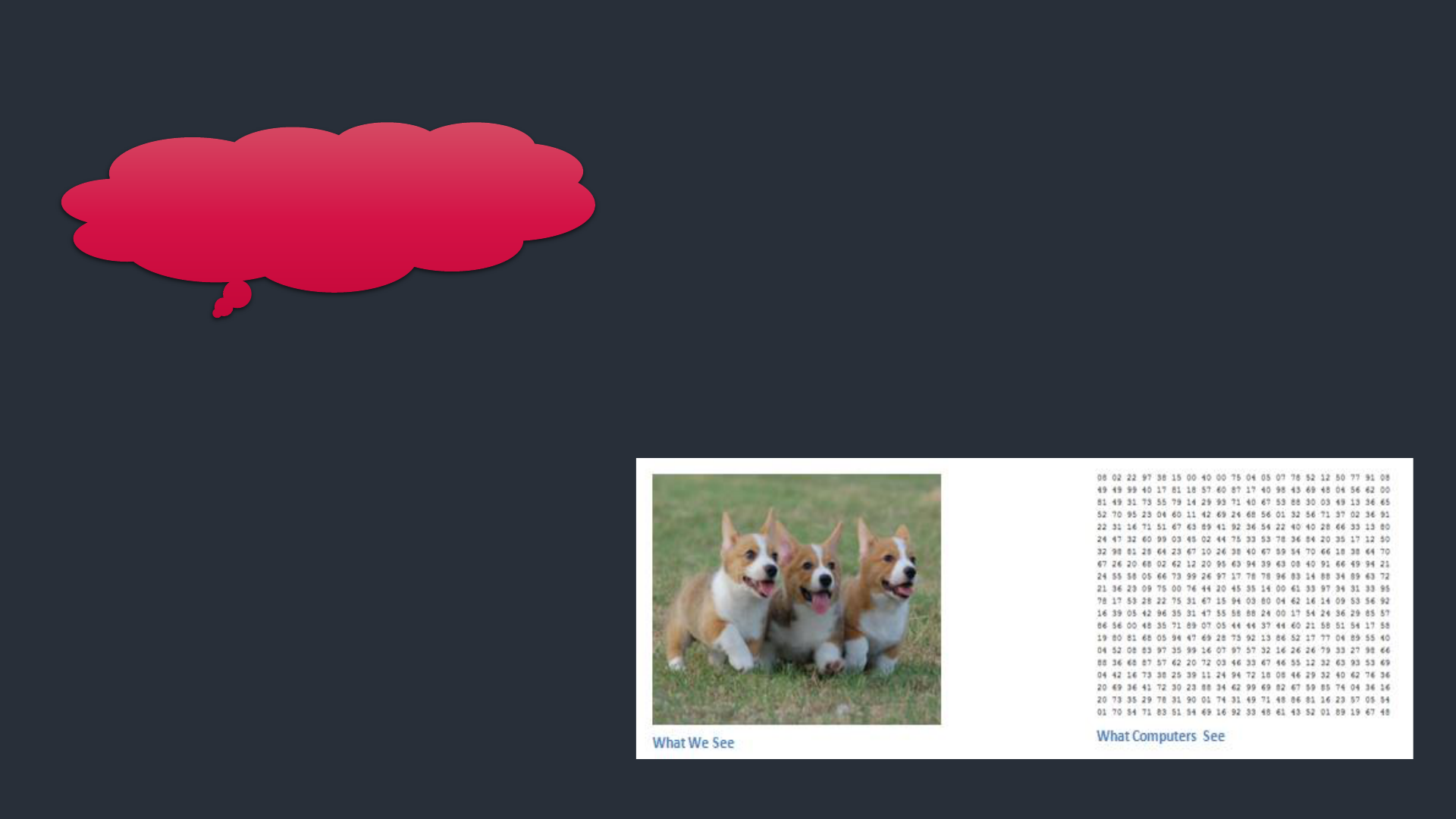
Girdiler ve Çıktılar
Bir bilgisayar bir görüntü gördüğünde(bir
görüntüyü giriş olarak alır), bir piksel
değerleri dizisi görecektir. Resmin
çözünürlüğüne ve boyutuna bağlı olarak, 32
x 32 x 3 sayı dizisi görecektir (3, RGB
değerlerini belirtir).
Bu sayıların her birine, o noktada
piksel yoğunluğunu açıklayan 0
ila 255 arasında bir değer verilir.
Buradaki fikir, bilgisayara bu sayı
dizisini vermeniz ve görüntünün
belirli bir sınıf olma olasılığını
açıklayan sayılar çıkarmasıdır

Bilgisayarın Ne
Yapmasını İstiyoruz?
Bilgisayarın yapmasını istediğimiz şey, verilen tüm
görüntüleri birbirinden ayırabilmek ve bir köpeği bir
köpek yapan ya da bir kediyi kedi yapan benzersiz
özellikleri bulmaktır. Aklımızda ve bilinçaltımızda da
devam eden süreç budur. Bir köpeğin resmine
baktığımızda, resmin, pençeleri veya 4 bacağı gibi
tanımlanabilir özelliklere sahip olması durumunda
onu sınıflandırabiliriz. Benzer şekilde bilgisayar,
kenarlar ve eğriler gibi düşük seviyeli özellikleri
arayarak ve daha sonra bir dizi konvolüsyon katmanı
yoluyla daha soyut kavramlara dayanarak görüntü
sınıflandırmasını gerçekleştirebilir.

Biyolojik Bağlantı
CNN’ler görsel
korteksten biyolojik bir
ilham alır. Görsel
korteks, görsel alanın
belirli bölgelerine
duyarlı küçük hücreli
bölgelere sahiptir.
Bu fikir, 1962’de Hubel ve
Wiesel tarafından yapılan
büyüleyici bir deney ile
genişletildi; burada beyindeki
bazı bireysel nöronal
hücrelerin sadece belirli bir
yönelimin kenarlarında
olduğunu (veya ateşlendiğini)
gösterdiler.
Hubel ve Wiesel, tüm
bu nöronların bir sütun
mimarisinde organize
edildiğini ve birlikte
görsel algı
üretebildiklerini
keşfetti.
Özel görevleri olan bir
sistemin içindeki özel
bileşenler fikri,
makinelerin de
kullandığı ve CNN’lerin
ardındaki temeldir.

Fully-Connected Layer
Sınıflamada kullanılan
Standart Sinir Ağı
Non-Linearity Layer
Sisteme doğrusal olma
yanlığın tanıtılması
Convolutional Layer
Özellikleri saptamak
için kullanılır
Pooling
(Downsampling) Layer
Ağırlık sayısını azaltır
ve uygunluğu kontrol
eder
Flattening Layer
Klasik Sinir Ağı için
verileri hazırlar
CNN
CNN’in Yapısı
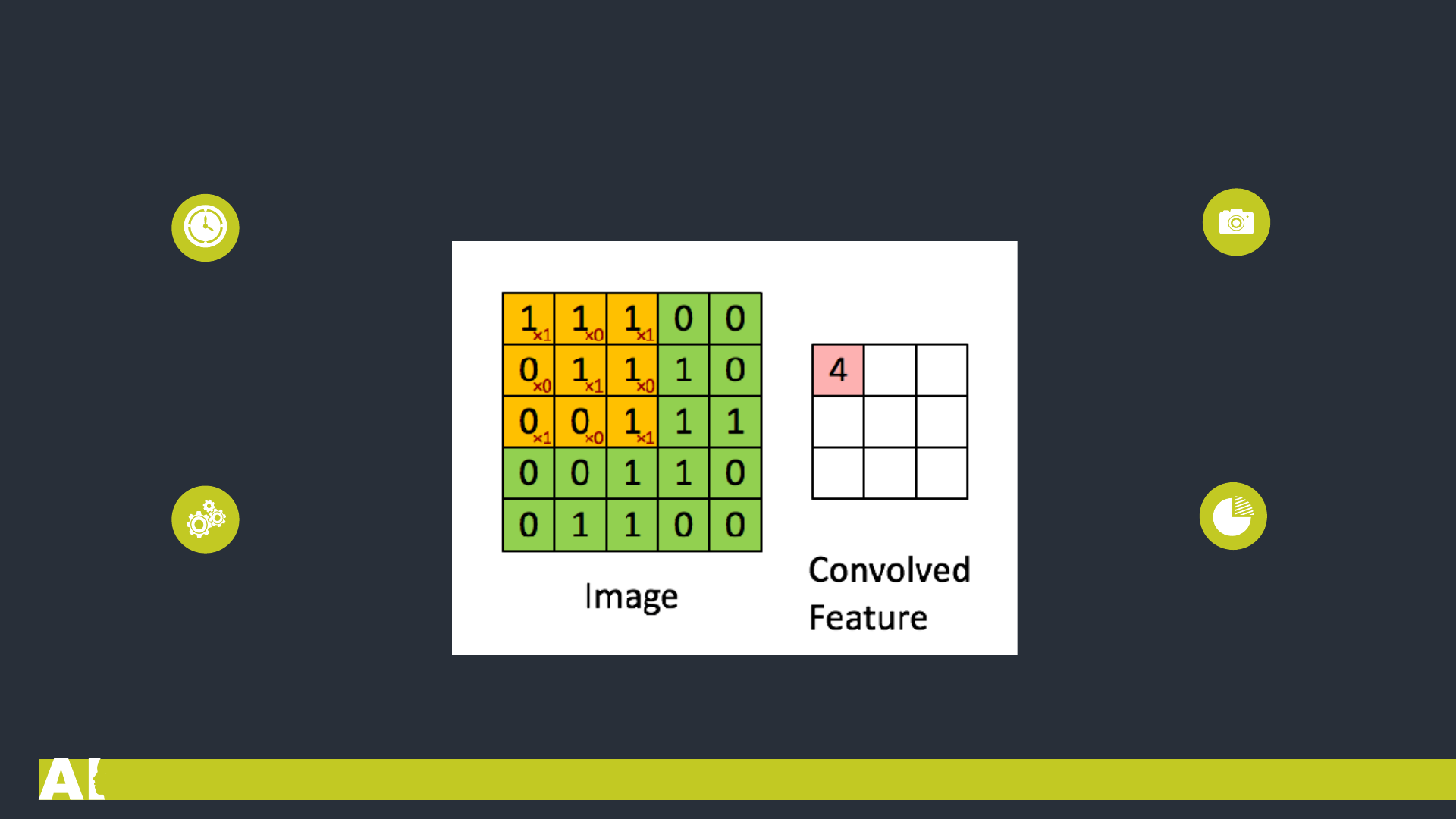
Convolutional Layer
Evrişimsel Katman 1
Bu filtreler genellikle çok
boyutludur ve piksel değerleri
içerirler.(5x5x3) 5 matrisin
yükseklik ve genişliğini, 3 matrisin
derinliğini temsil eder.
Öncelikle, filtre görüntünün sol üst
köşesine konumlandırılır. Burada, iki
matris arasında (resim ve filtre)
indisler bir birisi ile çarpılır ve tüm
sonuçlar toplanır, daha sonra sonucu
çıktı matrisine depolanır.
Bu katman CNN’nin ana yapı
taşıdır. Resmin özelliklerini
algılamaktan sorumludur.
Bu katman, görüntüdeki düşük ve
yüksek seviyeli özellikleri çıkarmak için
resme bazı fitreler uygular. Örneğin,
bu filtre kenarları algılayacak bir filtre
olabilir.
Peki çıktı matrisi bize ne anlatıyor?
Solda ki animasyona bir göz atalım,
burada bu işlem biraz daha görsel
olarak anlatılıyor.
4
Kısacası, filtreyi görüntü üzerinden
hareket ettirerek ve basit matris
çarpımını kullanarak, özelliklerimizi
tespit ediyoruz.
2
Birden çok özelliği tespit etmek için birden
fazla filtre kullanılır, yani bir Cnn ağında
birden fazla konvolüsyonel (Convolutional)
katman bulunur.
3
Bu matrise genellikle Feature Map denir. Filtre
tarafından temsil edilen özellikte görüntünün
bulunduğu yeri gösterir.
1

Yüksek Seviye Perspektif
Evrişimsel Katman 2
İlk filtreyi uyguladığımızda, bir
Feature Map oluşturuyor ve bir özellik
türünü tespit ediyoruz.
Ardından, ikinci bir filtre kullanıp başka bir
özellik türünü algılayan ikinci bir Feature
Map oluştururuz.
Stride (büyük adım) bu terim genellikle
padding terimi ile birlikte kullanılır. Stride,
filtrenin giriş görüntüsünün etrafında nasıl
evrildiğinini denetler.
Cnn’nin ilk aşamalarında, ilk filtreleri
uygularken, diğer Convolutional Katmanlar için
mümkün olduğunca çok bilgiyi korumamız
gerekir. İşte padding bu nedenden dolayı
kullanılır.
Feature Map’in orijinal giriş
görüntüsünden daha küçük olduğunu
fark etmişsinizdir. Bu nedenle Padding,
(aşağıdaki resimde olduğu gibi)resmin
boyutunu korumak için bu haritaya sıfır
değerler katacaktır.
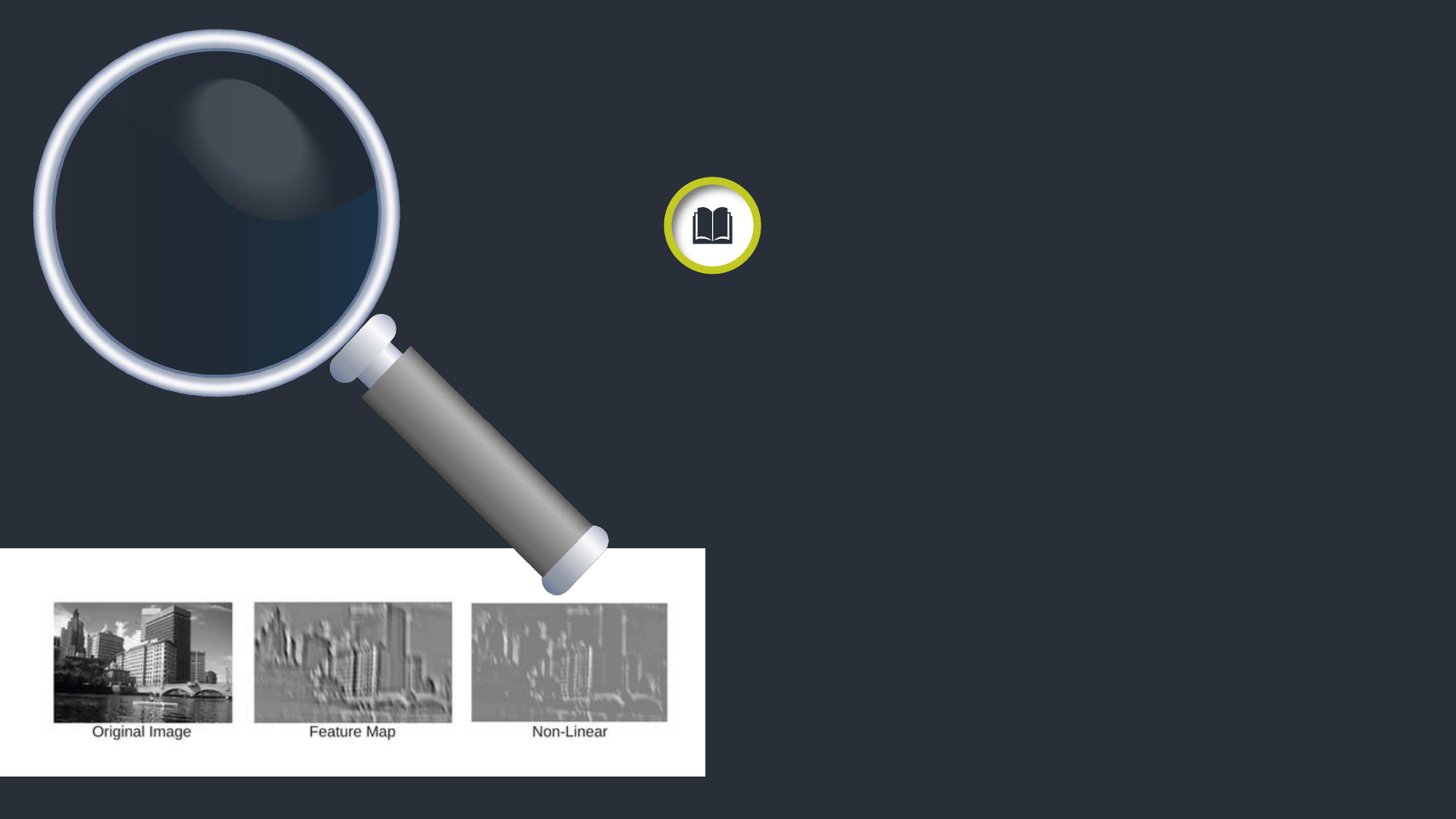
Non-linearity
Doğrusal olmayan
Tüm Convolutional katmanlarından
sonra genellikle Non-
Linearity(doğrusal olmayan) katmanı
gelir. Sorun şu ki, tüm katmanlar
doğrusal bir fonksiyon olabildiğinden
dolayı Sinir Ağı tek bir Perceptron gibi
davranır, yani sonuç, çıktıların linear
kombinasyonu olarak hesaplanabilir.
Bu katman aktivasyon katmanı
(Activation Layer) olarak adlandırılır
çünkü aktivasyon fonksiyonlarından
birini kullanılır.
Geçmişte, sigmoid ve tanh gibi
doğrusal olmayan fonksiyonlar
kullanıldı.
Feature Map’taki siyah değerler negatiftir. Relu
fonksiyonu uygulandıktan sonra siyah değerler kaldırılır
onun yerine 0 konur. Feature Map’taki siyah değerler
negatiftir. Relu fonksiyonu uygulandıktan sonra siyah
değerler kaldırılır onun yerine 0 konur.
ReLu Fonksiyonu f (x) = max (0, x)
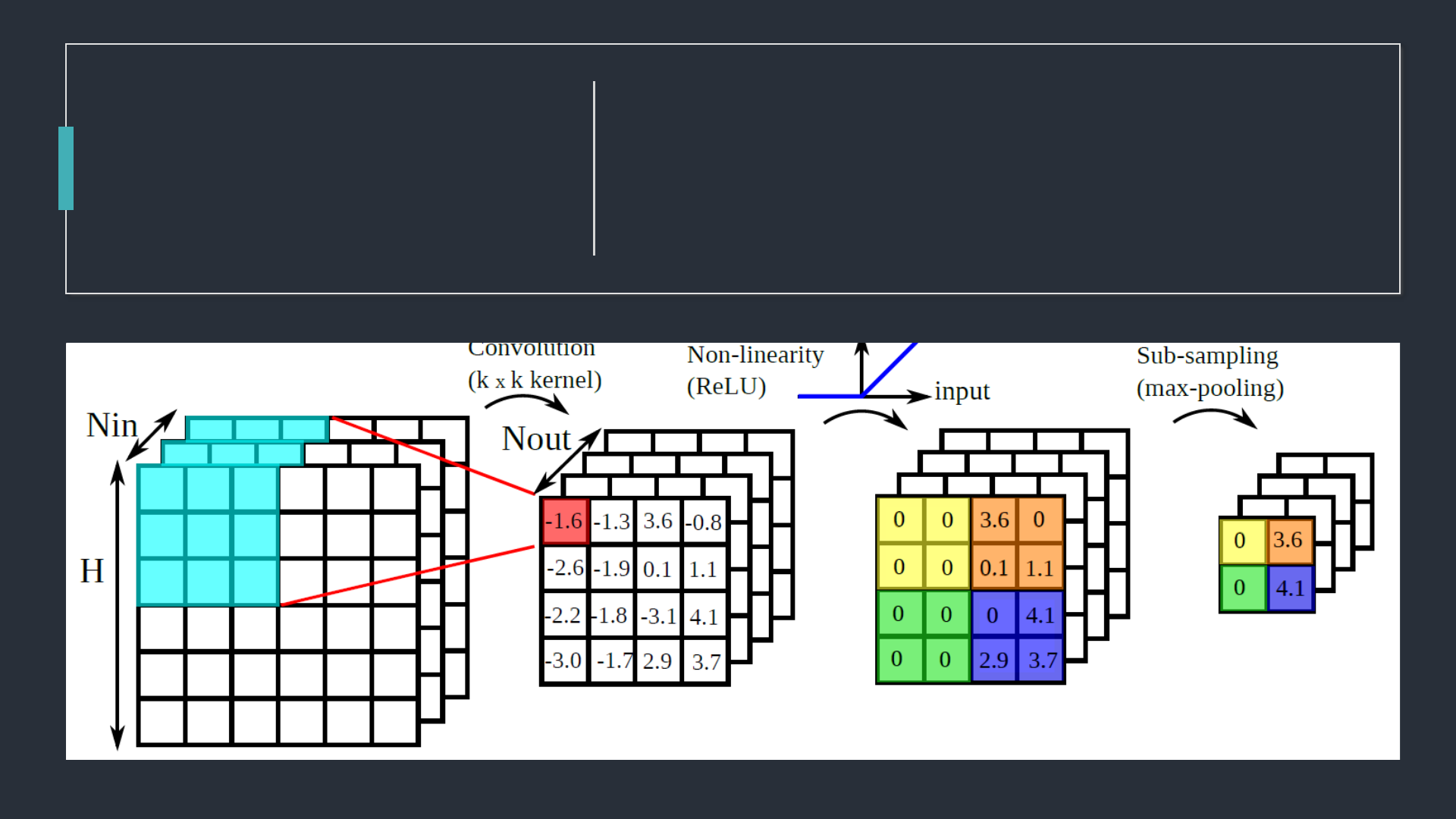
Pooling Layer
Bu katman, CovNet’teki
ardışık convolutional
katmanları arasına sıklıkla
eklenen bir katmandır. Bu
katmanın görevi, gösterimin
kayma boyutunu ve ağ
içindeki parametreleri ve
hesaplama sayısını azaltmak
içindir.
Bu sayede ağdaki uyumsuzluk
kontrol edilmiş olur. Birçok
Pooling işlemleri vardır, fakat en
popüleri max pooling’dir. Yine
aynı prensipte çalışan average
pooling, ve L2-norm pooling
algoritmalarında vardır.
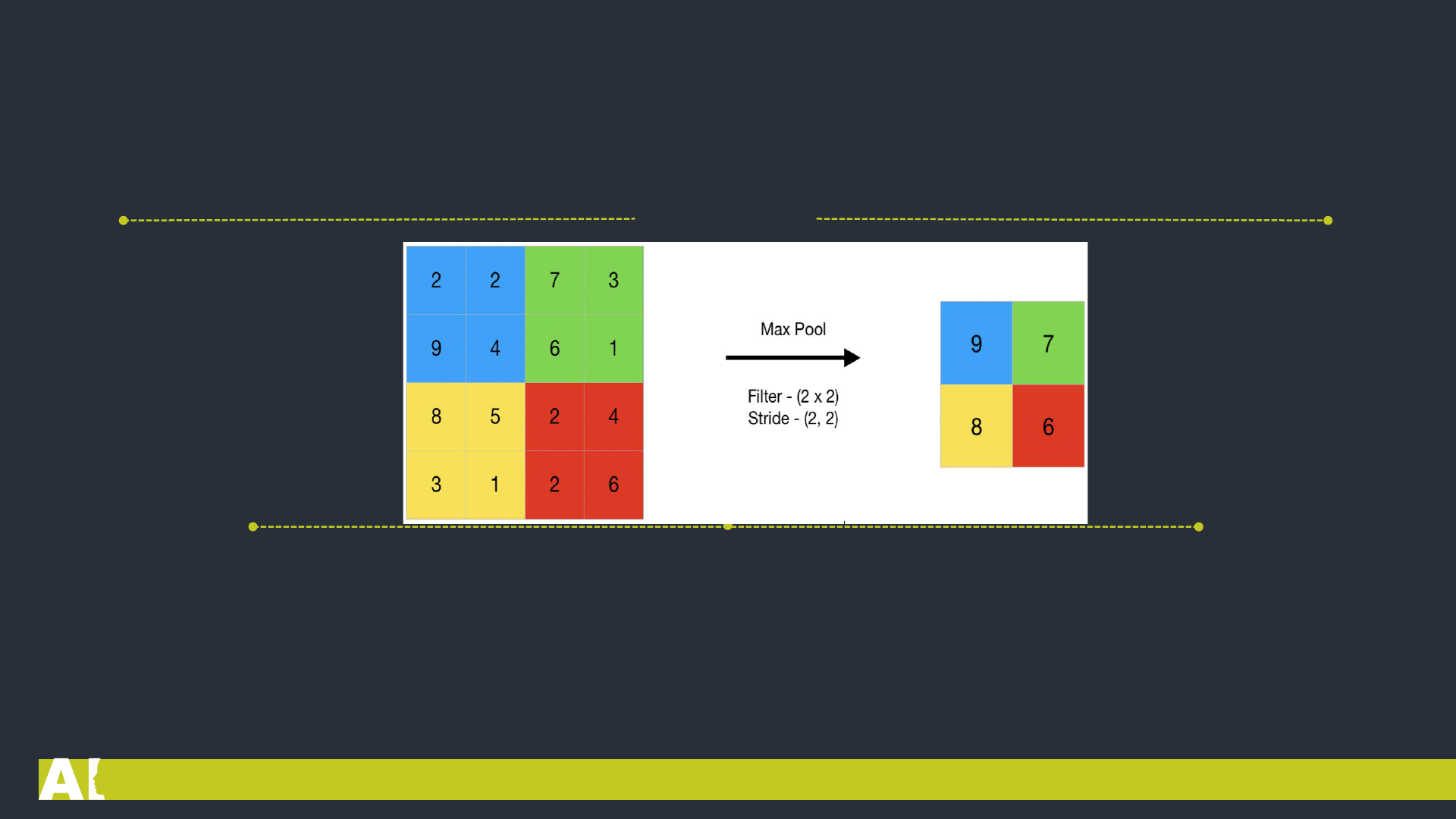
Öncelikle 2×2 boyutunda bir filtre oluşturalım. Bu filtreyi yukarıdaki (4×4) resim üzerinde görebilirsiniz. Resimde
gördüğünüz gibi, filtre, kapsadığı alandaki en büyük sayıyı alır. Bu sayede, sinir ağının doğru karar vermesi için yeterli bilgiyi
içeren daha küçük çıktıları kullanmış olur. Bununla birlikte birçok kişi bu katmanı kullanmayı tercih etmez. Bunun yerine
Convolutional katmanında daha büyük Stride (Filtreyi kaydırma işlemi) tercih edilir. Ayrıca variational autoencoders (VAEs)
or generative adversarial networks (GANs) gibi daha üretken modellerde pooling katmanını tamen çıkartırlar.

Flattening Layer
Bu katmanın görevi, son
ve en önemli katman olan
Fully Connected Layer’ın
girişindeki verileri
hazırlamaktır.
Genel olarak, sinir ağları,
giriş verilerini tek boyutlu
bir diziden alır. Bu sinir
ağındaki veriler ise
Convolutional ve Pooling
katmanından gelen matrixlerin
tek boyutlu diziye çevrilmiş
halidir.
You can simply impress
your audience and add a
unique zing and appeal
to your Presentations.
Bu katman ConvNet’in son
ve en önemli katmanıdır.
Verileri Flattening
işleminden alır ve Sinir ağı
yoluyla öğrenme işlemini
geçekleştirir.
Fully
Connected
Layer
Evrişimsel Sinir Ağlarının Mimarileri
Convolution+Relu
Softmax
Flatten
Fully connected
pooling
pooling
Feature Learning
Özellik Öğrenimi
Convolution+Relu
Classification
Sınıflandırma
RELU:
Rectified Linear
Unit
Doğrultulmuş
Doğrusal Birim
Evrişim+DDB
Evrişim+DDB
Düzeltir
Tamamen bağlı

Eğitim
Olayı kendimizden ele alırsak;
biz büyüdükçe,
ebeveynlerimiz ve
öğretmenlerimiz bize farklı
resim ve görüntüleri bize
uygun bir etiket olarak
öğretti. Bir resim ve bir etiket
verilmesi fikri, CNN’lerin
geçtiği eğitim sürecidir.

Test yapmak
30%
45%
60%
80%
90%
CNN’mizin işe yarayıp
yaramadığını görmek için farklı
bir dizi resim ve etikete
sahibiz. Görüntüleri CNN’den
geçiriyoruz. Çıktıları temel
gerçekle karşılaştırırız ve
ağımızın işe yarayıp
yaramadığını görebiliriz!

Şirketler CNN’leri Nasıl Kullanıyor?
Veri, veri, veri. Bu büyülü 4 harfli kelimeye
sahip olan şirketler, rekabetin geri kalanı
boyunca doğal bir avantajı olanlardır. Bir ağa
verebileceğiniz daha fazla eğitim verisi,
yapabileceğiniz daha fazla eğitim
tekrarlaması, yapabileceğiniz daha fazla
ağırlık güncellemesi ve ağın daha iyi
ayarlanması, üretime gitmesidir. Facebook
(WhatsApp, Instagram), şu anda sahip
olduğu 2 milyar kullanıcının tüm
fotoğraflarını kullanabilir, Pinterest,
sitesinde bulunan 50 milyar resmin
bilgilerini kullanabilir, Google arama
verilerini kullanabilir ve Amazon,
milyonlarca ürünün verilerini kullanabilir.
Bunlar her gün satın alınır.

Veri Setleri aramak
V
E
R
İ

RNN
Recurrent Neural Networks

• Recurrent Neural Networks (RNN) ‘ü anlayabilmek için önce
feedforward(ileri doğru çalışan) bir ağın çalışma prensibini tekrar
inceleyelim. Kısaca katmanlar üzerindeki nöronlara gelen bilgilere bir
takım matematiksel işlemler uygulayarak çıktı üreten bir yapı
diyebiliriz.
• Feedforward çalışan yapıda gelen bilgi sadece ileri doğru işlenir. Bu
yapıda kabaca, input verileri ağdan geçirilerek bir output değeri elde
edilir. Elde edilen output değeri doğru değerler ile karşılaştırılarak
hata elde edilir. Ağ üzerindeki ağırlık değerleri hataya bağlı olarak
değiştirilir ve bu şekilde en doğru sonucu çıktı verebilen bir model
oluşturulmuş olur.
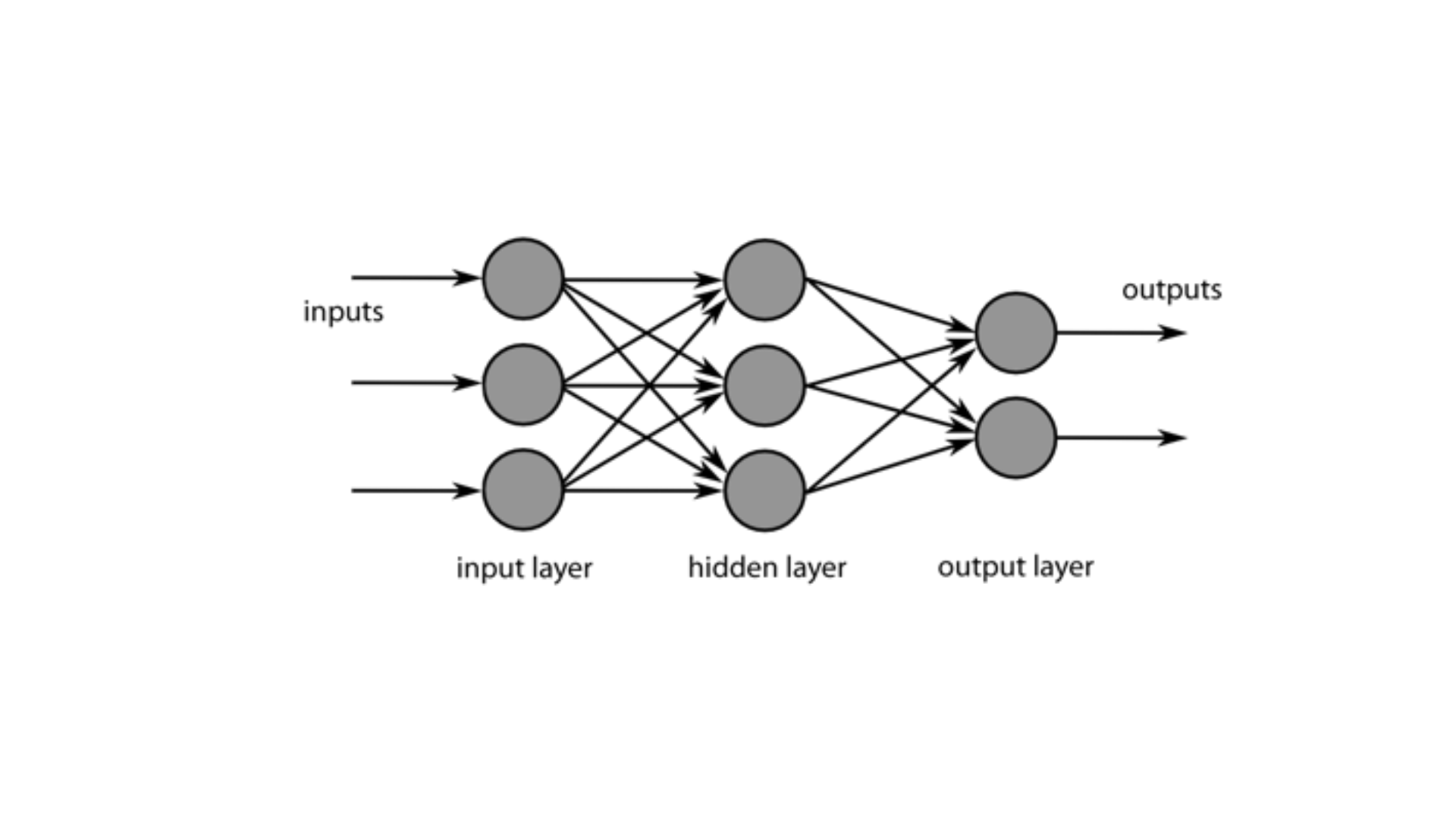

• Feedforward bir ağın eğitiminde hatanın yeterince düşürülmesi
gerekir. Böylece nöronlara giden ağırlıklar yenilenerek girilen inputa
uygun output verecek bir yapı oluşmuş olur.
• Örneğin, bir fotoğraf üzerindeki nesneleri kategorize etmek için
eğitilen feedforward bir ağ düşünelim. Verilen fotoğraf rastgele bir sıra
ile de olsa hem eğitim hem de test için kullanılabilir. Bir önceki veya
bir sonraki fotoğraf ile herhangi bir bağının olması gerekmez. Yani
zamana veya sıraya bağlı bir kavram yoktur, ilgilendiği tek input o
andaki mevcut örnektir.

• Recurrent(yinelenen) yapılarda ise sonuç, sadece o andaki inputa değil,
diğer inputlara da bağlı olarak çıkarılır. Şekilde de görüleceği gibi RNN’de t
anındaki input verilerinin yanında, t-1 anından gelen hidden layer
sonuçları da hidden layer’ın t anındaki girdisidir. t-1 anındaki input için
verilen karar, t anında verilecek olan kararı da etkilemektedir. Yani bu
ağlarda inputlar şimdiki ve önceki bilgilerin birleştirilmesi ile output
üretirler.
• Recurrent yapılar, outputlarını sonraki işlemde input olarak kullandıkları için
feedforward yapılardan ayrılmış olurlar. Recurrent ağların bir belleğe sahip
olduğunu söyleyebiliriz. Bir ağa memory eklemenin sebebi ise, belli bir
düzende gelen input setinin, çıktı için bir anlamı olmasıdır. Bu çeşit data
setleri için feedforward ağlar yeterli olmaz.
• Tam bu noktada RNN’ler devreye girer. Yazı, konuşma, zamana bağlı çeşitli
sensör veya istatiksel veriler gibi belli bir sıra ile gelen verilerin yapısını
anlamada recurrent ağlar kullanılır.
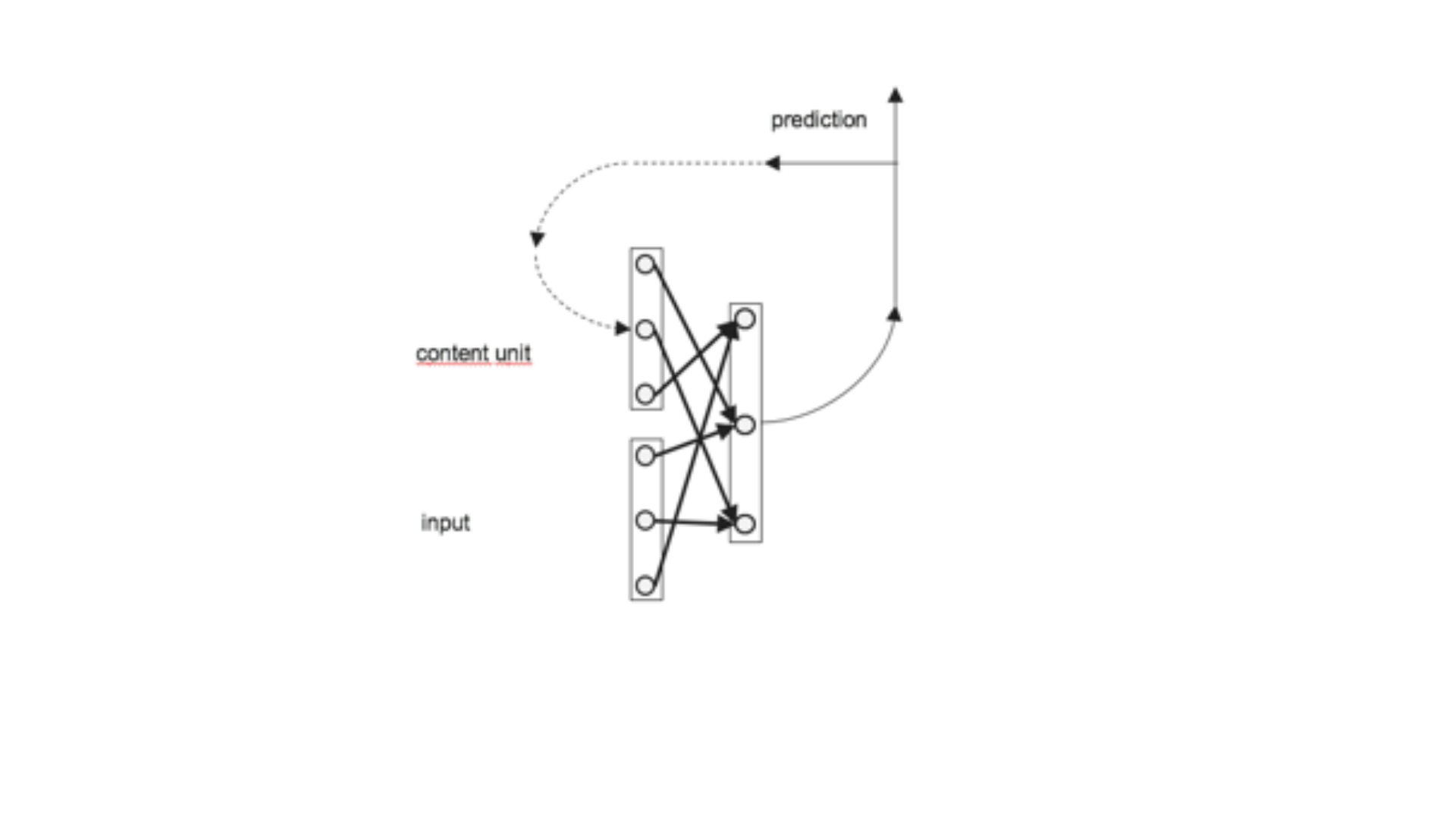

• Diagramda görüldüğü gibi , RNN’in işlem döngüsünde hidden
layer’dan çıkan sonuç hem output üretir, hem content unitlere yazılır.
Bu şekilde, her yeni input, önceki inputların işlenmesi sonucu
üretilmiş content unitlerle birlikte işlenir. Farklı zamanlarda belleğe
alınan veriler arasında korelasyon bulunuyorsa buna “long term”
bağımlılık denir. RNN, bu long-term bağımlılıkların arasındaki ilişkiyi
hesaplayabilen bir ağdır.
• İnsanların davranışlarında, konuşma ve düşüncelerinde de bu yapıdaki
gibi önceden memory’de olan bilgi tıpkı bir hidden layer’da yeni veri
ile döngüye girerek işlenir. Bu işlemi yaparken kullanılan matemetiksel
formül aşağıdaki gibidir.

• ht, t anındaki hidden layer’ın sonucudur. xt inputu W ağırlığı ile
çarpılır. Daha sonra t-1 anında, content unit ‘te tutulan h(t-1) değeri U
ağırlığı ile çarpılır ve Wxt ile toplanır. W ve U değerleri girdi ile katman
arasındaki ağırlıklardır. Burada ağırlık matrisi önceki ve şimdiki verinin
hangisinin sonuca etkisi daha çok veya az ise ona göre değerler alır. Bu
işlemler sonucunda oluşan hata hesaplanır ve backpropagation ile
yeni ağırlık değerleri tekrar düzenlenir. Backprop işlemi hata yeterince
minimize edilene kadar devam eder. Wxt + Uh(t-1) toplamı sigmoid,
tanh gibi aktivasyon fonksiyonuna sokulur. Böylece çok büyük veya
çok küçük değerler mantıklı bir aralığa alınır. Bu şekilde non-lineerlik
de sağlanmış olur.
Örnek Bir
Recurrent
Neural
Network

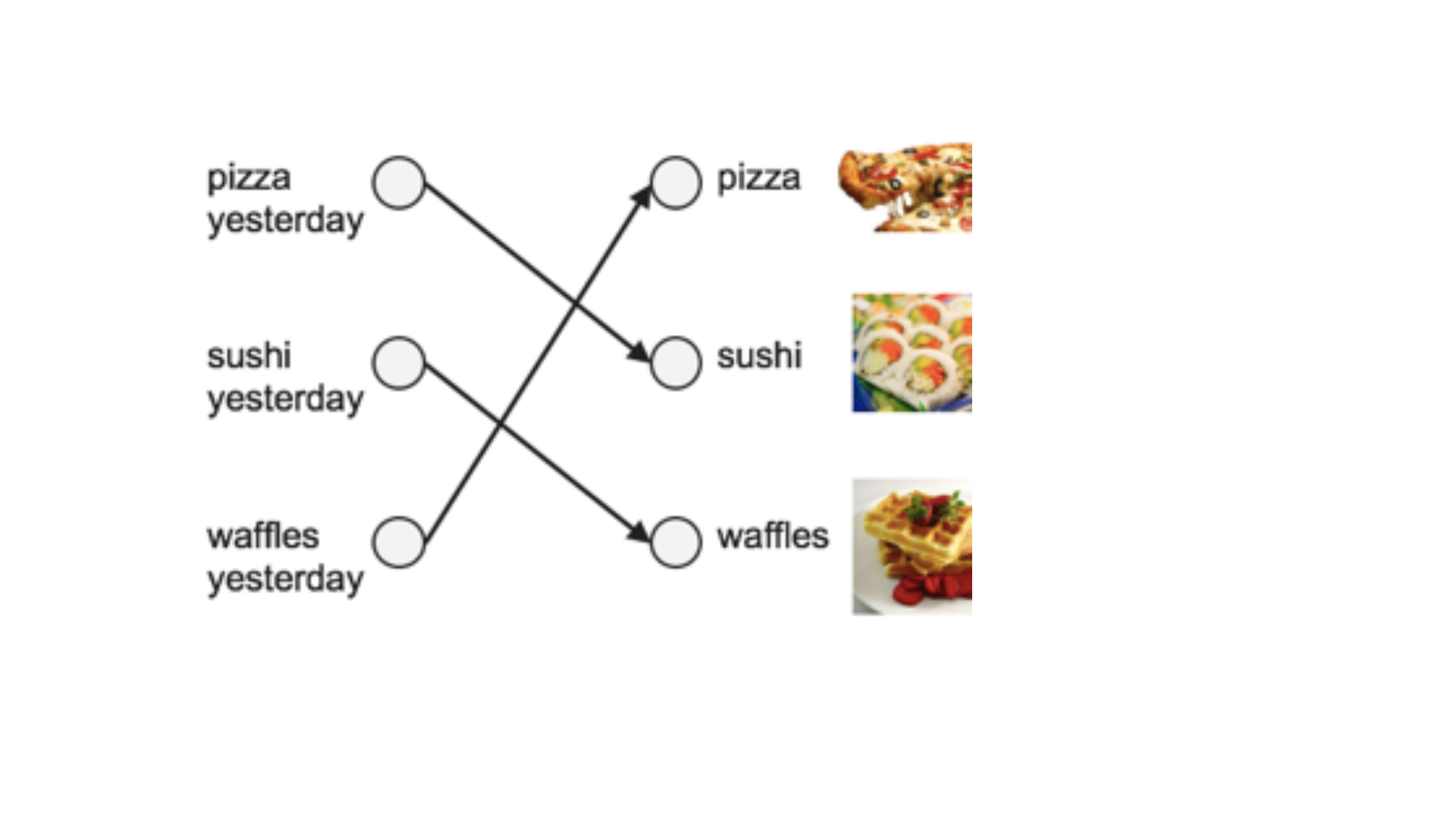
• Bir aşçının 3 farklı yemeği sırasıyla yaptığını düşünelim. 1. gün pizza
yaptıysa 2. gün sushi 3. gün waffle yapıyor olsun. Bir sonraki gün ne
yapacağını tahmin etmemiz gerekiyorsa öncelikle nasıl bir problemle
karşı karşıya olduğumuz anlayarak, bu probleme uygun bir metot
kullanmamız gerekir. Burada yemek bir sıraya göre geldiği için, yani
önceki gün yapılan yemeğin sonraki günde etkisi olacağı için
uygulanması gereken metot recurrent neural network metodudur. Bu
sayede elimizdeki bilgilerle yeni bilgi olmasa dahi birkaç hafta sonraki
günde yapılacak yemeği dahi tahmin edebiliriz.
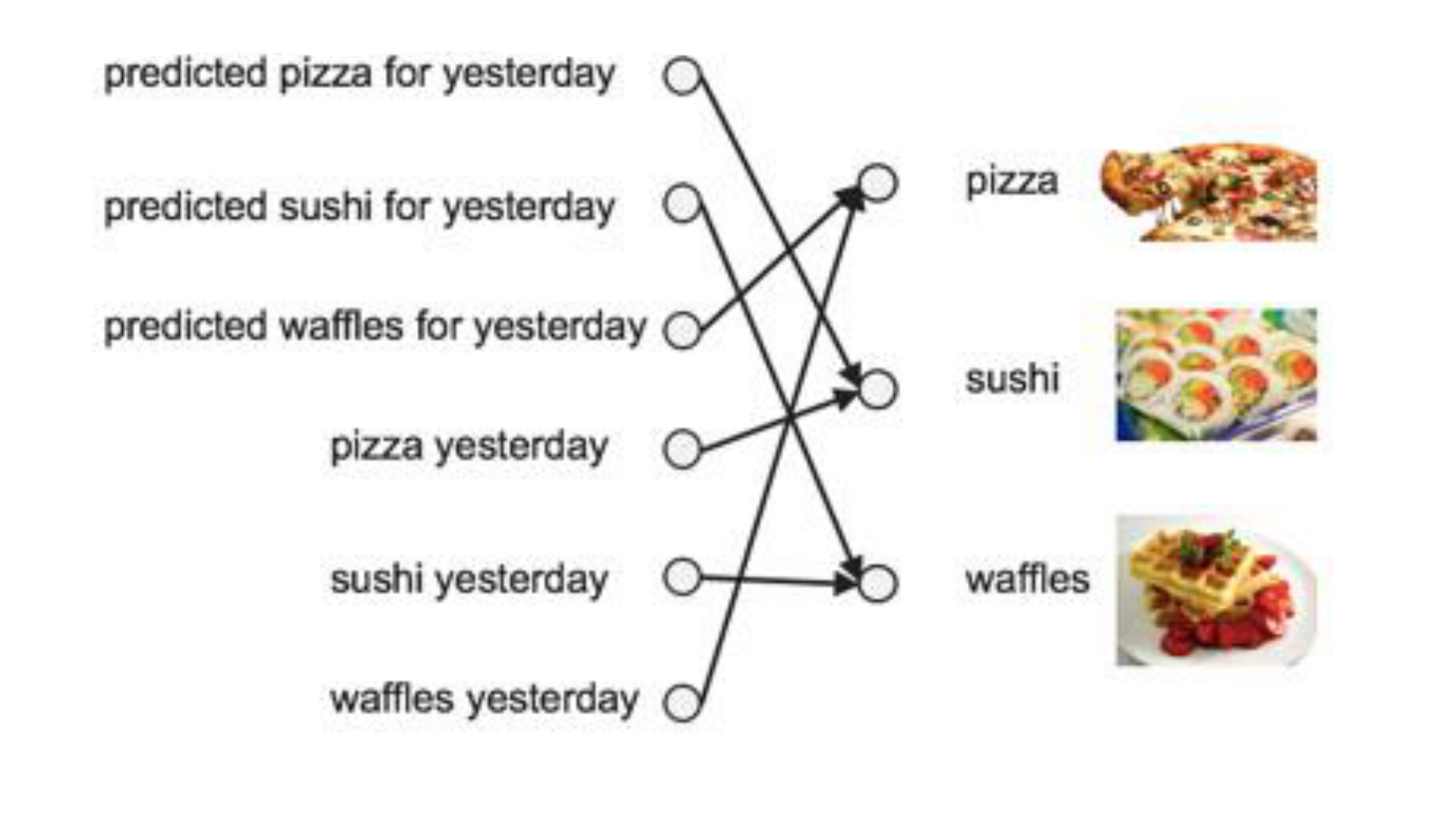

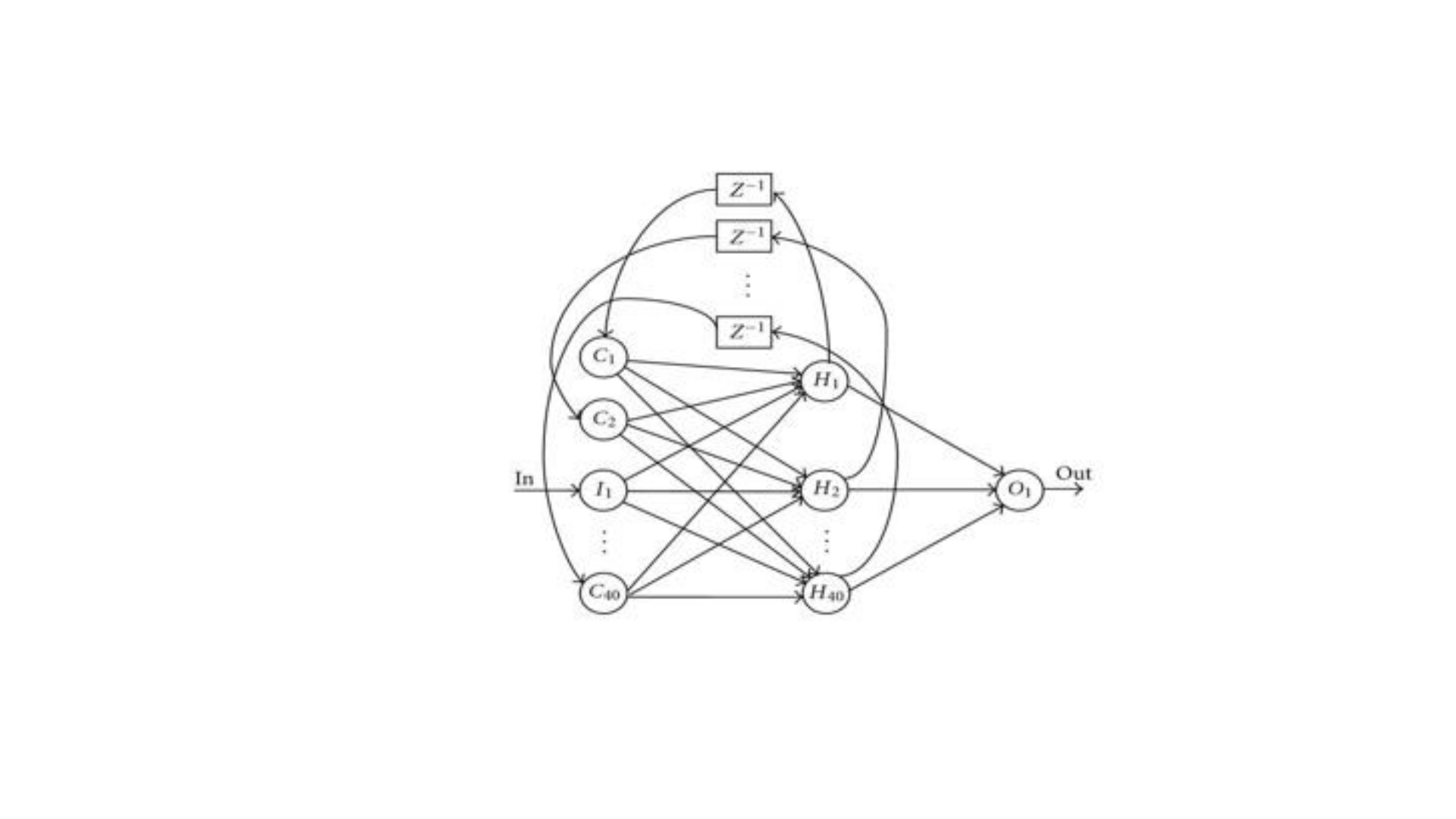
Backpropagation Trough Time(BPTT)
• Recurrent ağların amacı sıralı inputları doğru bir şekilde sınıflandırmak
diyebiliriz. Bu işlemleri yapabilmek için hatanın backpropunu ve
gradient descentini kullanırız. Backprop, feedforward ağlarda sonda
outputtaki hatayı geriye hatanın türevini ağırlıklara dağıtılarak yapılır.
Bu türev kullanılarak öğrenme katsayısı, gradient descent
düzenlenerek hatayı düşürecek şekilde ağırlıklar düzenlenir.
• RNN için kullanılan yöntem ise BPTT diye bilinen zamana bağlı sıralı bir
dizi hesaplamanın tümü için backprop uygulamasıdır. Yapay ağlar bir
dizi fonksiyonu içiçe f(h(g(x))) şeklinde kullanır. Buraya zamana bağlı
değişken eklendiğinde türev işlemi zincir kuralı ile çözümlenebilir.
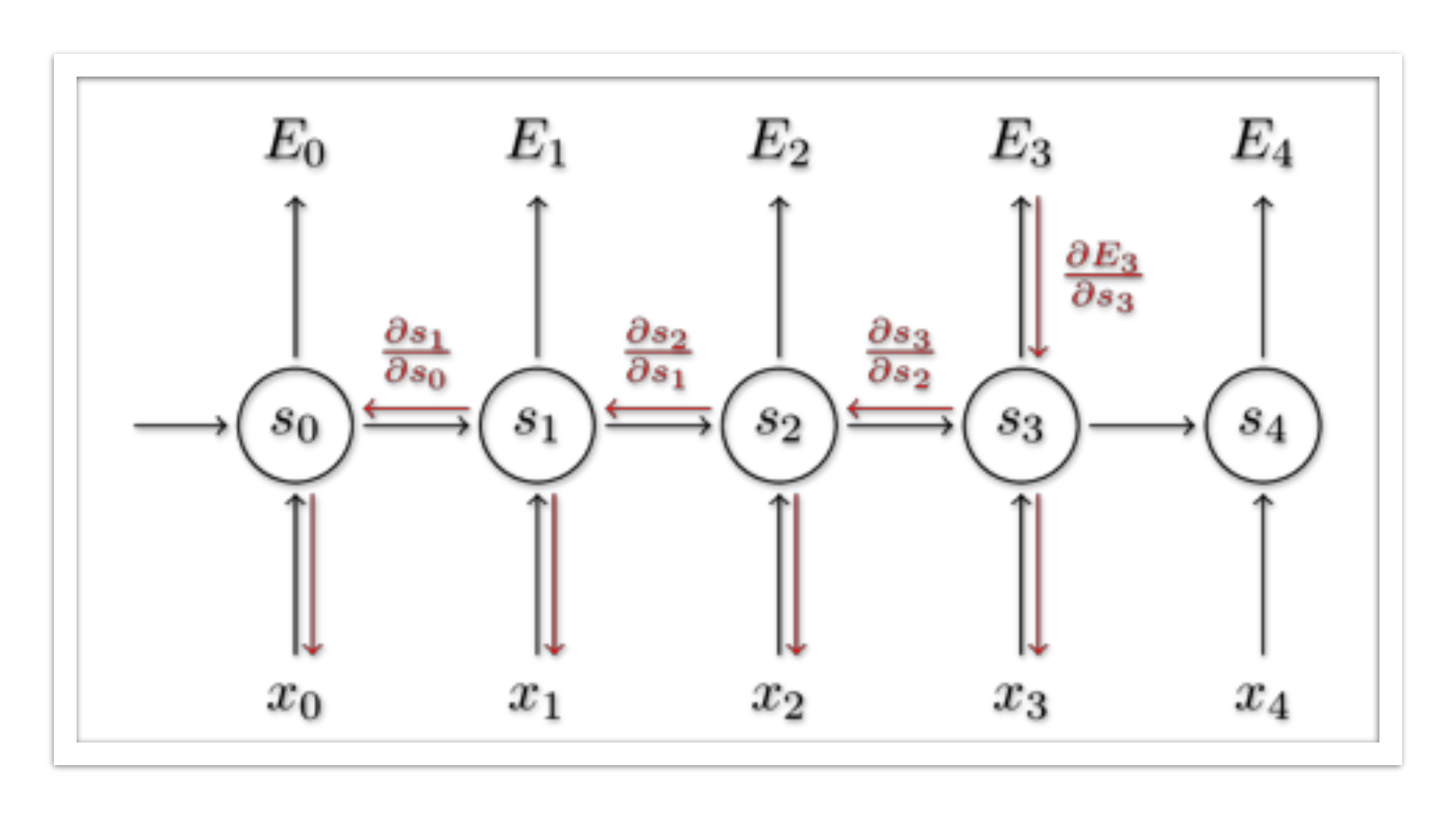
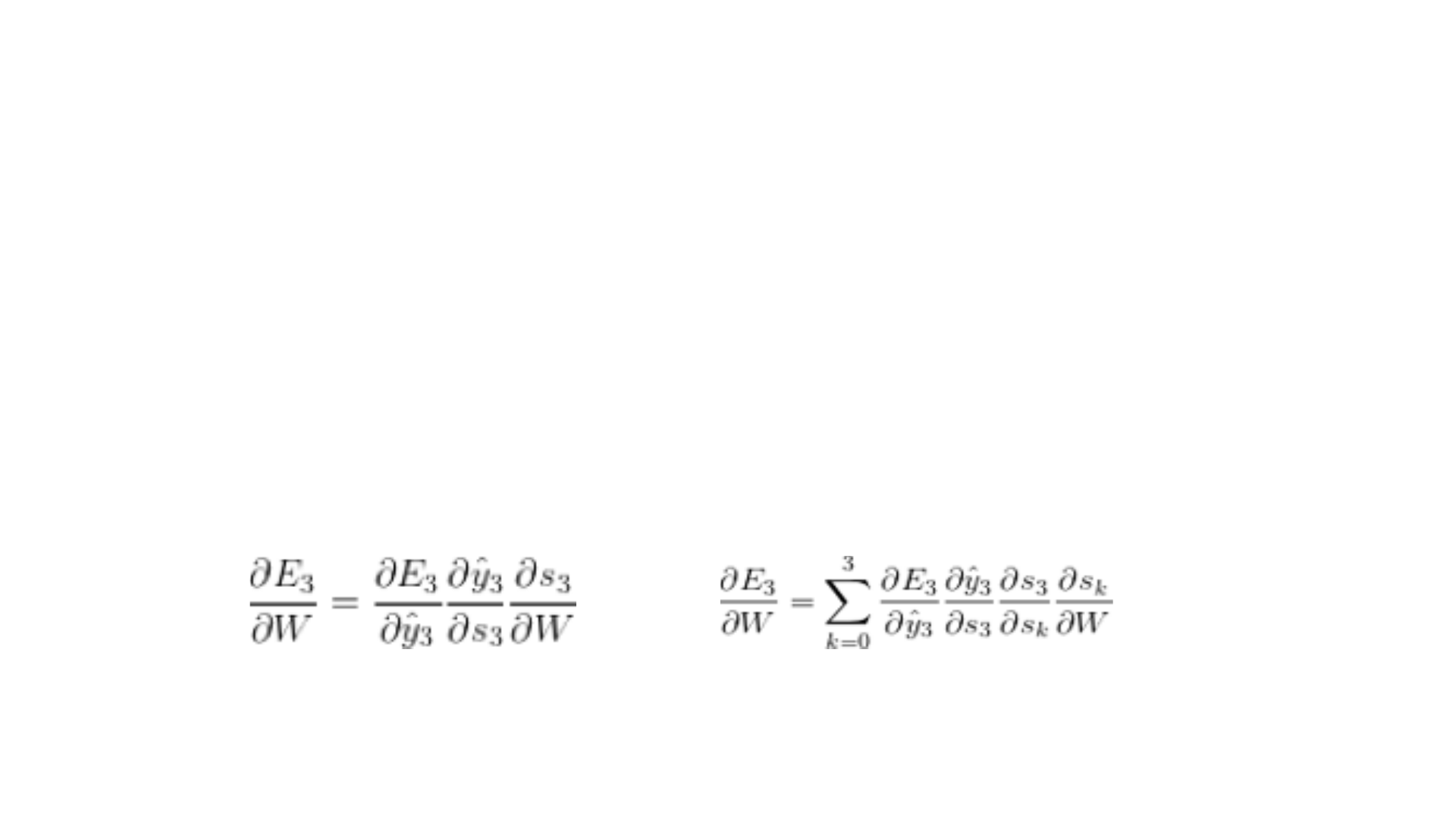
• Yukardaki RNN’in çalışma mantığı anlatılmıştır. Üstteki figürde ise sıralı
5 girdili bir recurrent ağ yapısı gösterilmektedir. E burada oluşan
hatayı ifade etmektedir. Örneğin, E3 için backpropagation yaparken
yaptığımız işlemde w ağırlığına göre türevi kullanılmaktadır. Bu türevi
çözebilmek için zincir kuralı ile birkaç türevin çarpımını kullanırız.

• Bu çarpım yukarıda gösterildiği gibidir. Burada s3’ün açılımında s2’ye
bir bağımlılık bulunur. Bunu çözebilmek için yine zincir kuralını
kullanarak s3’ün s2’ye türevini de ekleyerek sonucu bulabiliriz.
Böylece formüldeki gibi gradient zamana bağlı şekilde dağıtılmış olur.

Truncated BPTT
• Truncated BPTT ise BPTT ‘nin uzun bir sıralı veri için bir çok ileri, geri
işlemler çok masraflı olacağından, BPTT için yaklaşım yapar. Bunun
kötü yanı gradient kesilmiş hesaplandığından ağ “long term”
bağımlılıkları full BPTT kadar iyi öğrenemez.
• Vanishing/Exploding Gradient ( Gradient yokolması/uçması)
• Gradient tüm ağırlıkları ayarlamamızı sağlayan bir değerdir. Ancak
birbirine bağlı uzun ağlarda hatanın etkisi oldukça düşerek gradient
kaybolmaya başlayabilir. Bu da doğru sonucu bulmayı olanaksızlaştırır.
Bütün katmanlar ve zamana bağlı adımlar birbirine çarpımla bağlı
olduğundan, türevleri yokolma veya uçma yani aşırı yükselme
tehlikesindedir.
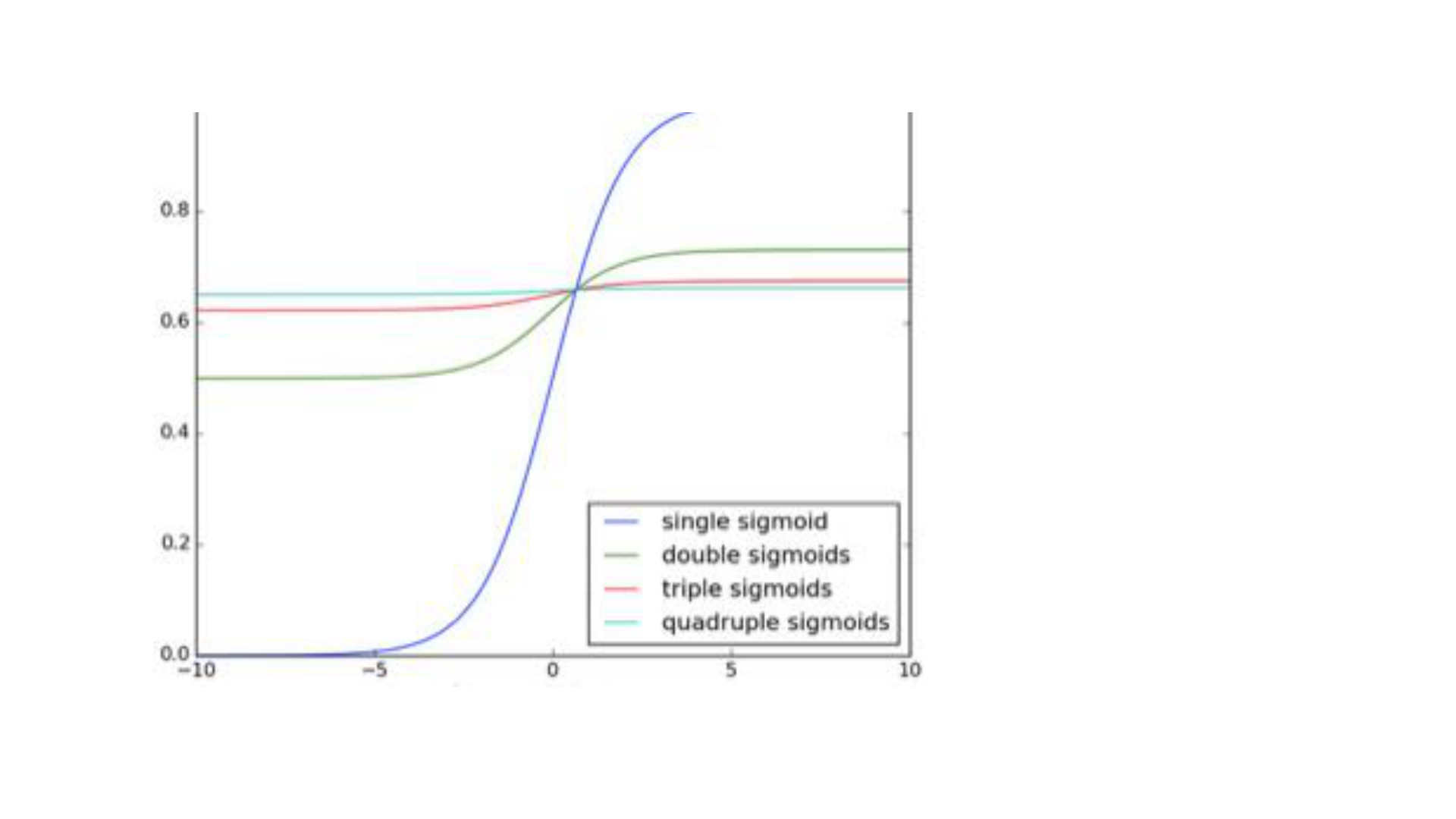

• Gradient exploding yani aşırı büyümesi ağın çok büyük değerler
üretmesini sağlayarak doğru sonuçtan uzaklaştıracaktır. Bunun için
threshold koyarak çok yüksek değerli gradientleri kesmek basit ve
etkili yollardan biridir. Gradientlerin aşırı küçülerek yokolması ise çok
daha zor bir problemdir. Nerde, ne zaman durdurulması gerektiği çok
açık değildir.
• Neyse ki bu sorunu çözmek için de birkaç çözüm bulunmaktadır. W
için uygun başlangıç değerleri seçmek yokolma etkisini azaltacaktır. Bir
diğer çözüm ise sigmoid ve tanh aktivasyon fonksiyonları yerine ReLU
kullanmaktır. ReLU fonksiyonunun türevi 0 veya 1’dir. Bu sebepten
böyle bir problem içerisine girmeyecektir. Bir diğer yöntem ise bu
problemi çözmek için dizayn edilmiş olan LSTM metodudur.

Long Short Term Memory (LSTM)
• Sepp Hochreiter ve Juergen Schmidhuber 1997 yılında vanishing
gradient problemini çözmek için LSTM’i geliştirdiler. Daha sonra birçok
kişinin katkısıyla düzenlenen ve popülerleşen LSTM şu anda geniş bir
kullanım alanına sahiptir.
• LSTM backprop’ta farklı zaman ve katmanlardan gelen hata değerini
korumaya yarıyor. Daha sabit bir hata değeri sağlayarak recurrent
ağların öğrenme adımlarının devam edebilmesini sağlamaktadır. Bunu
sebep sonuç arasına yeni bir kanal açarak yapmaktadır.
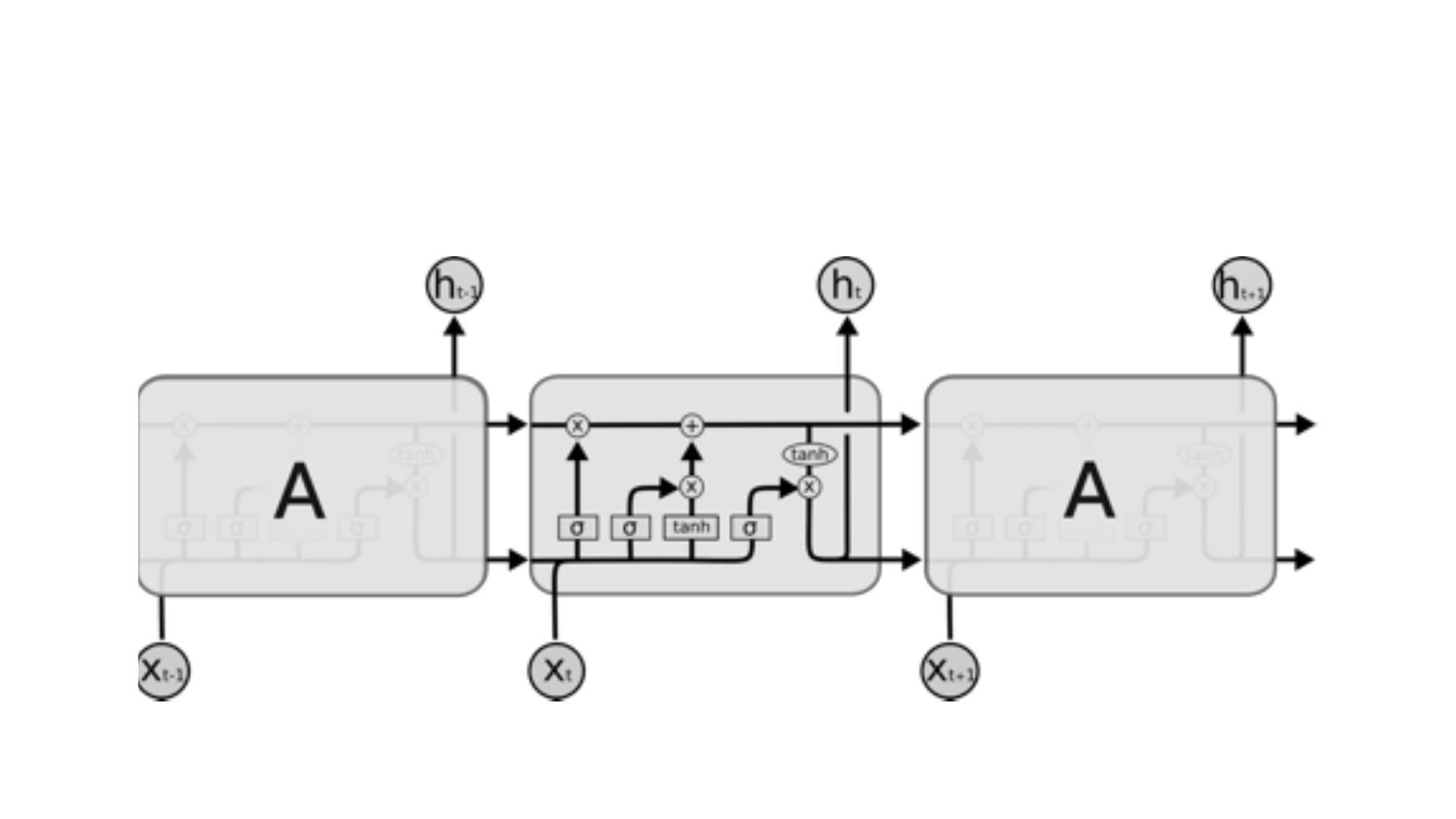

• LSTM yapısında tekrar eden modülün farkı tek bir neural network
katmanı yerine, özel bir şekilde bağlı 4 katman bulunmasıdır. Bu
katmanlara kapı da denmektedir. Normal akışın dışında dışarıdan
bilgi alan bir yapıdır. Bu bilgiler depolanabilir, hücreye yazılabilir,
okunabilir.
• Hücre neyi depolayacağını, ne zaman okumasına, yazmasına veya
silmesine izin vereceğini kapılar sayesinde karar verir. Bu kapılarda
bir ağ yapısı ve aktivasyon fonksiyonu bulunmaktadır. Aynı
nöronlarda olduğu gibi gelen bilgiyi ağırlığına göre geçirir veya
durdurur. Bu ağırlıklar recurrent ağın öğrenmesi sırasında hesaplanır.
Bu yapı ile hücre, datayı alacak mı bırakacak mı silecek mi öğrenir.
• Aşağıdaki diyagramlarda bir LSTM hücresi adım adım anlatılmıştır.
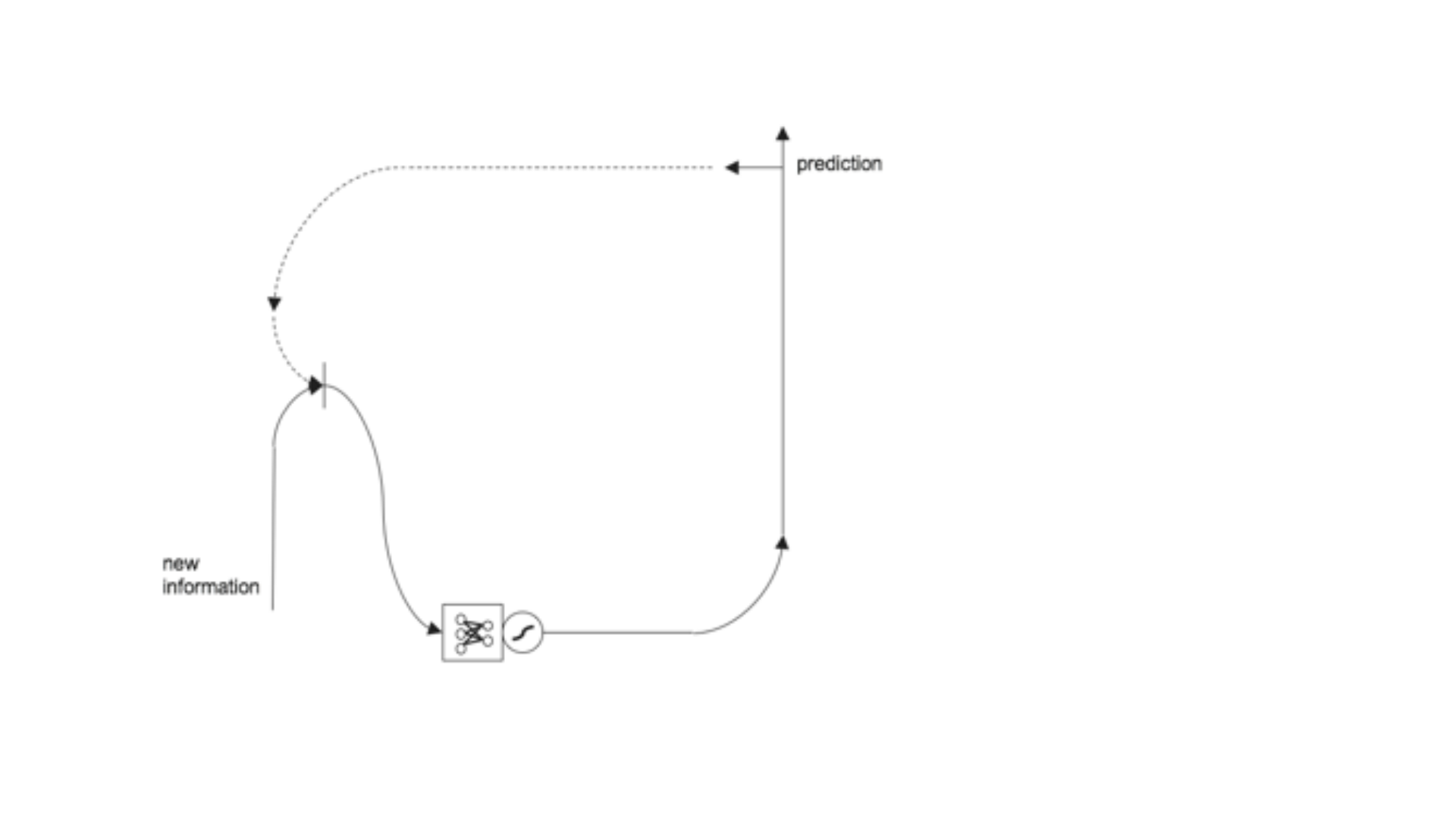
• Birinci diyagramda normal RNN
çalışma sistemi gösterilmiştir. İkinci
diyagramda ise birinciden farklı
olarak hücreye bellek eklenmiştir.
Bunu yaparak, uzun süre önceki
verileri de kullanarak karar
verilmektedir.
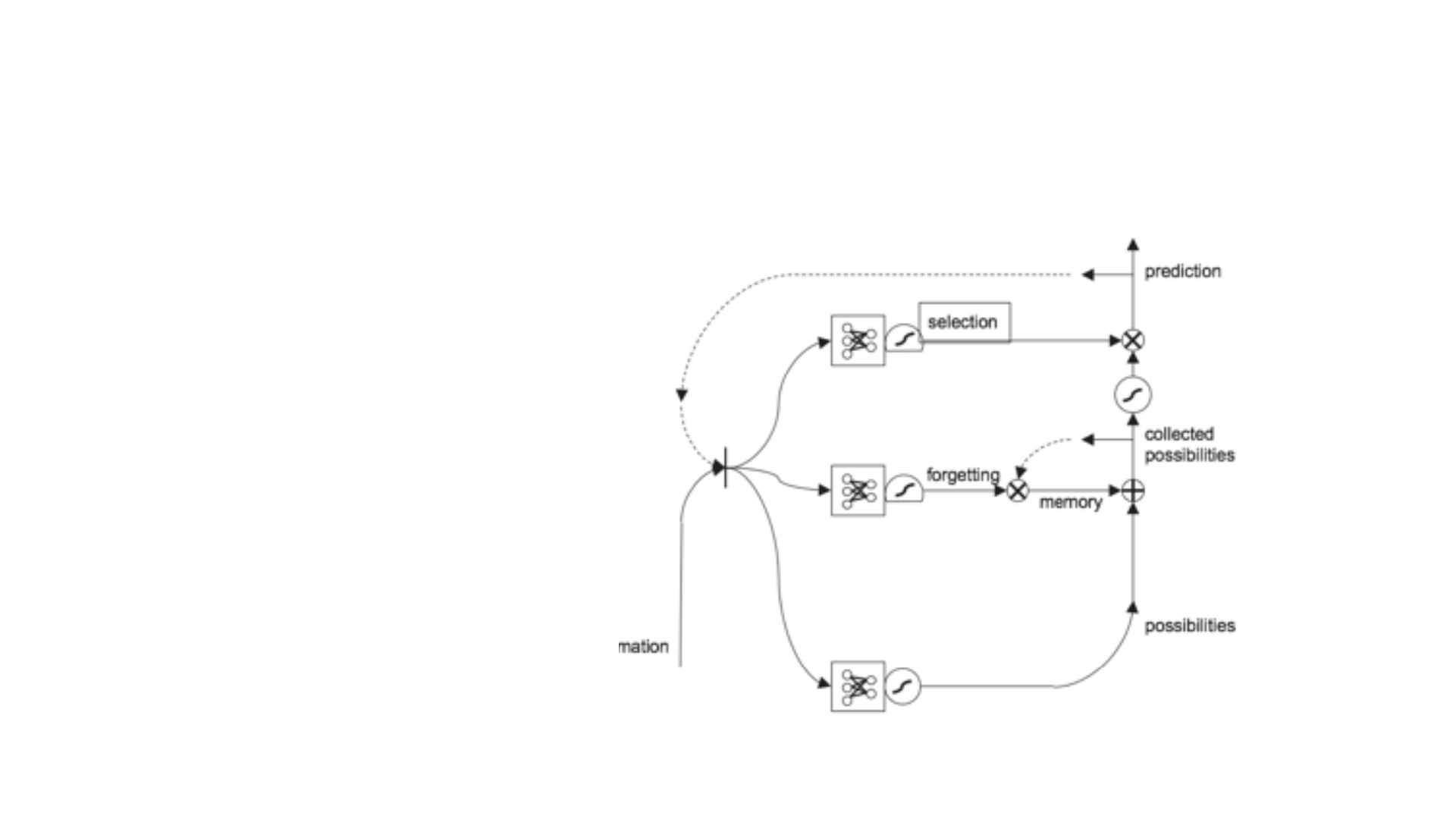
• Diyagramda görülen + işareti
element bazda toplama işlemini
göstermektedir. x işareti ise
element bazda çarpım işlemidir.
Element bazda yapılan çarpma
işlemi ile verinin hangisinin ne kadar
kullanılıp kullanılmayacağı,
bellekteki verilerin ağırlıklarla
çarpılması ile hesaplanır. Daha
sonra + işlemi ile bellekten gelen ile
olasılıktan gelen toplanarak bir
tahmin üretilir.
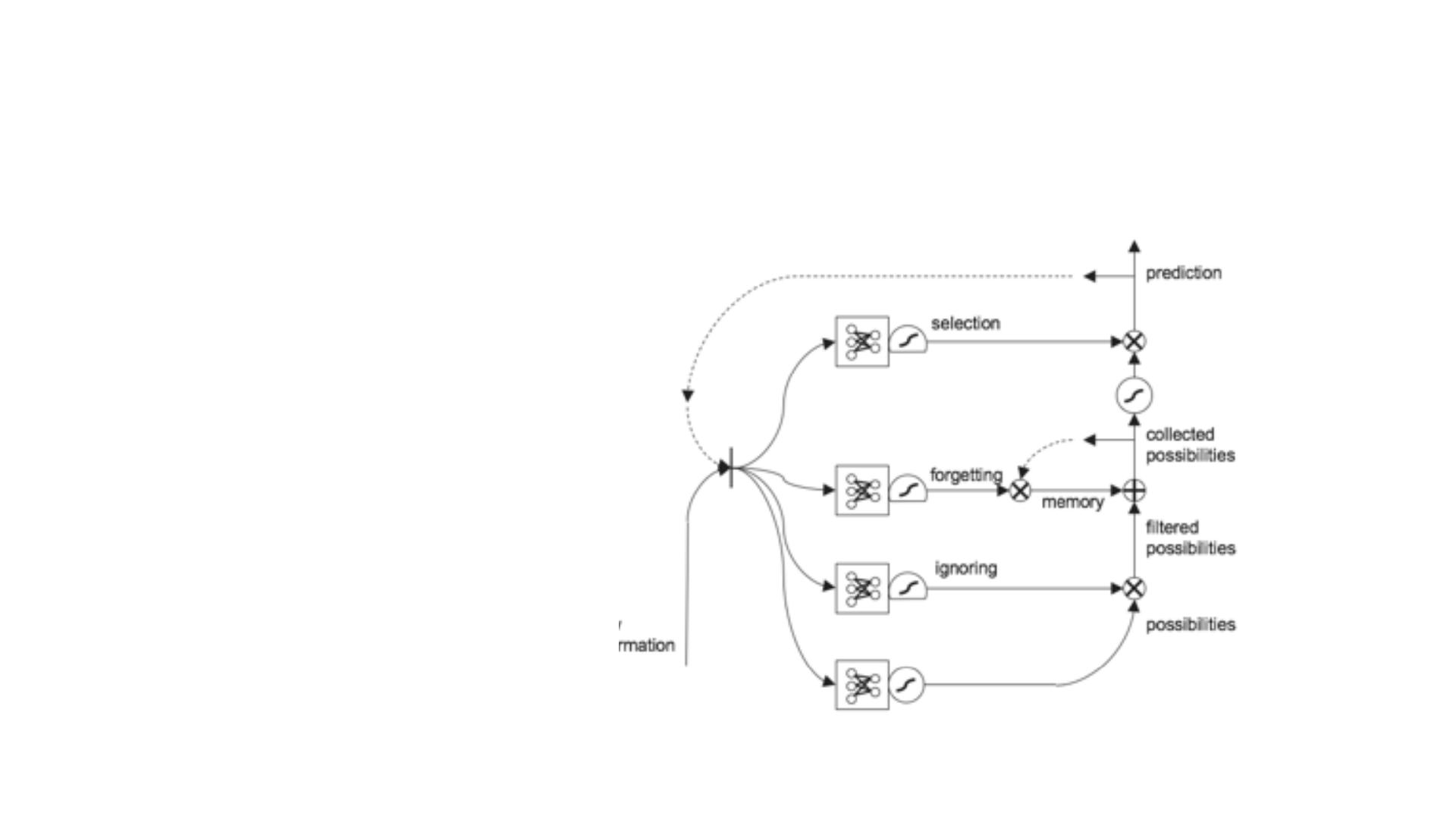
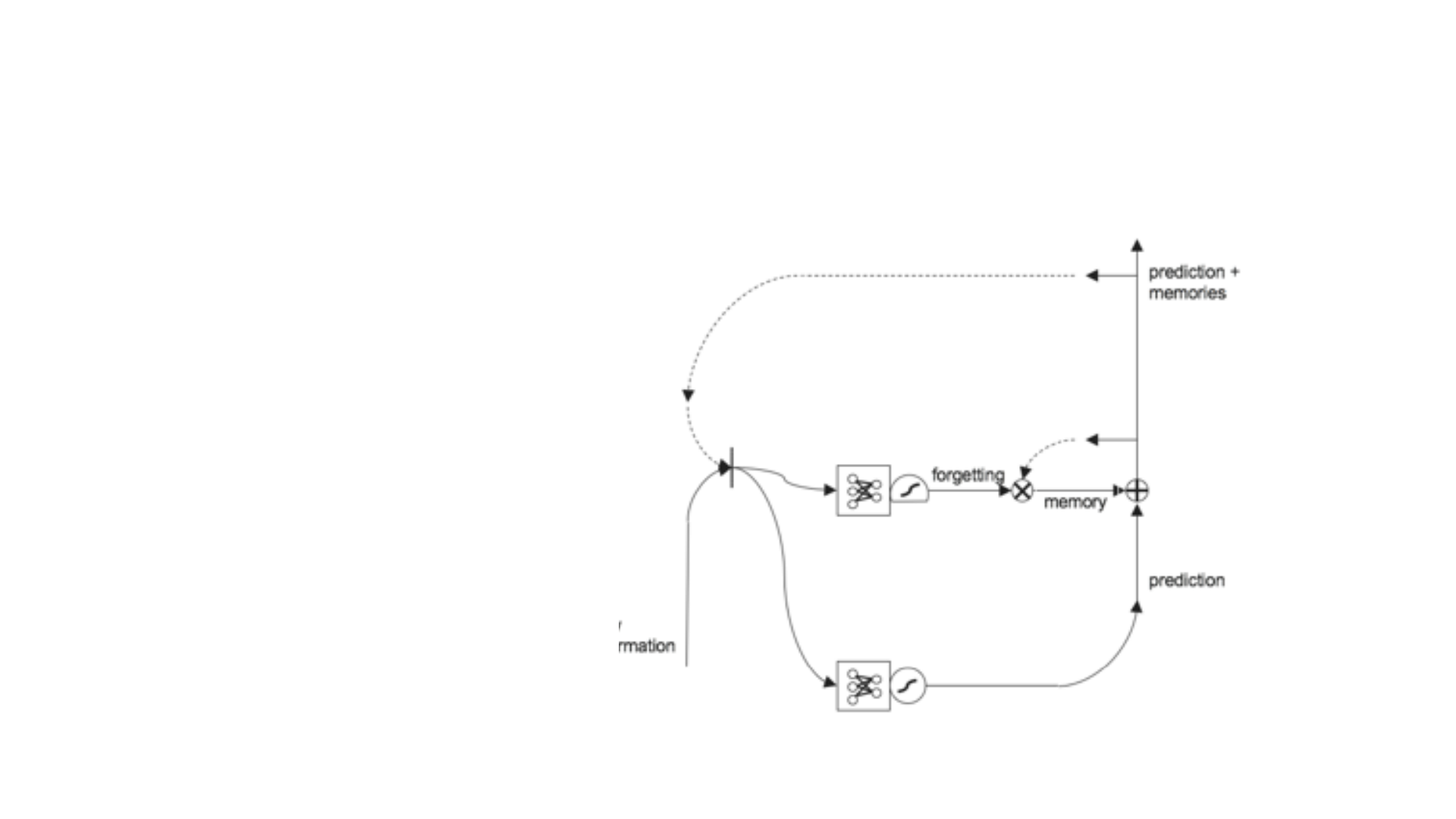
• Bu diyagramda ise yeni bir kapı
daha eklenmiştir. Bu kapı toplama
işlemi yapıldıktan sonra hangisini ne
kadar kullanacağımızı seçmek için
bir filtre bir bölümdür. Bu bölümde
bellekte verileri tutup tahminden
ayırma işlemi yapılır. Yine bu kapı da
kendine özgü bir neural networke
sahiptir.

• Bir diğer kapı ise yine ilk gelen olasılıkları bellekten gelenlerle
toplamadan önce filtreleme için kullanılır. Yine burada da bir ağ yapısı
vardır. Gelen sonuçlar element bazda çarpılarak diğer işleme geçer.
Böylece belleğe gitmesi gerekmeyen veriler filtrelenmiş olurlar.
• LSTM’in farklı ihtiyaçlara göre farklı modelleri bulunmaktadır. Bunlar
yukarıda söylediğimiz kapıların girdilerini farklı yerlerden alması veya
çıktılarını farklı yerlere göndermesi ile sağlanmıştır.

Multi Layer Perceptron (MLP)
(Çok Katmanlı Algılayıcılar) Nedir?

Tanım:
Bildiğiniz gibi, beynimiz milyonlarca nörondan oluşur, bu nedenle bir
sinir ağı, sadece farklı yollarla bağlanan ve farklı aktivasyon
fonksiyonlarında çalışan perceptronların bir bileşimidir.
Multi-layer Perceptron(MLP) yani Çok Katmanlı Algılayıcılar, Yapay Sinir
Ağları’na olan ilgiyi hızlı bir şekilde artırmıştır.

XOR
Çok Katmanlı Algılayıcılar
(MLP) XOR Problemini
çözmek için yapılan
çalışmalar sonucu ortaya
çıkmıştır.Rumelhart ve
arkadaşları tarafından
geliştirilen bu modeli ‘Back
Propogation Model’ yada
hatayı ağa yaydığı için ‘Hata
Yayma Modeli’ de
denmektedir.
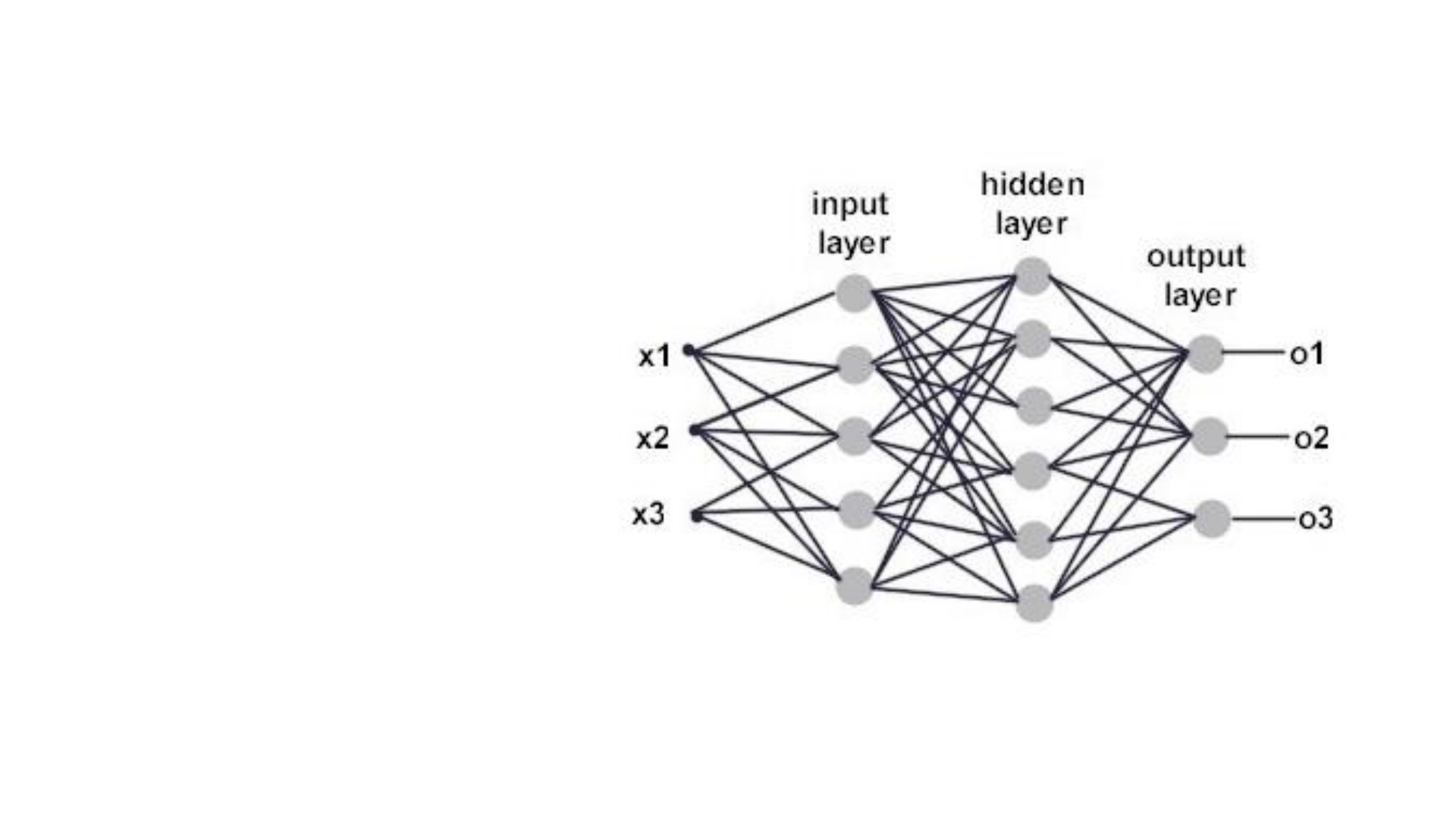
MLP
özellikle sınıflandırma ve
genelleme yapma
durumlarında etkin çalışır.
Çok Katmanlı Ağ’ ların
yapısı aşağıdaki gibidir.

Birçok giriş için bir nöron yeterli olmayabilir. Paralel işlem yapan birden
fazla nörona ihtiyaç duyulduğunda katman kavramı devreye girer.
Görüldüğü üzere Single Perceptron Model’den farklı olarak arada gizli(
hidden) katman bulunmaktadır. Giriş katmanı gelen verileri alarak ara
katmana gönderir. Gelen bilgiler bir sonraki katmana aktarılırlar. Ara
katman sayısı en az bir olmak üzere probleme göre değişir ve ihtiyaca
göre ayarlanır. Her katmanın çıkışı bir sonraki katmanın girişi olmaktadır.
Böylelikle çıkışa ulaşılmaktadır. Her işlem elemanı yani nöron bir sonraki
katmanda bulunan bütün nöronlara bağlıdır. Ayrıca katmandaki nöron
sayısı da probleme göre belirlenir. Çıkış katmanı önceki katmanlardan
gelen verileri işleyerek ağın çıkışını belirler. Sistemin çıkış sayısı çıkış
katmanında bulunan eleman sayısına eşittir.
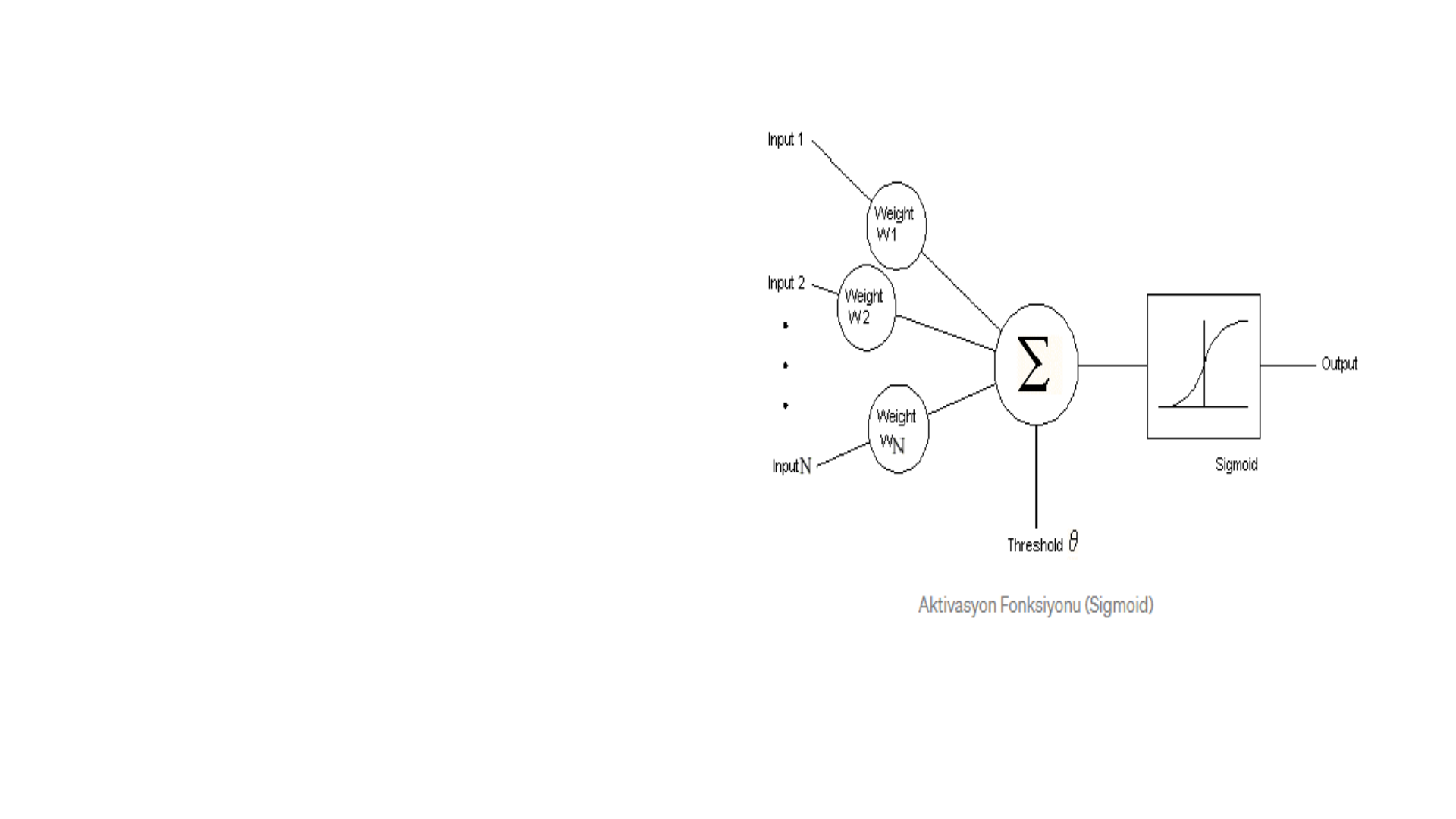
Modelde aktivasyon
fonksiyonu olarak herhangi bir
matematiksel fonksiyon
kullanılabilir. Ancak Sigmoid,
tang, lineer, threshold ve hard
limiter fonksiyonları en çok
kullanılan fonksiyonlardır.
Çok katmanlı ağda
öğrenme Delta Öğrenme
Kuralı tabanlıdır.
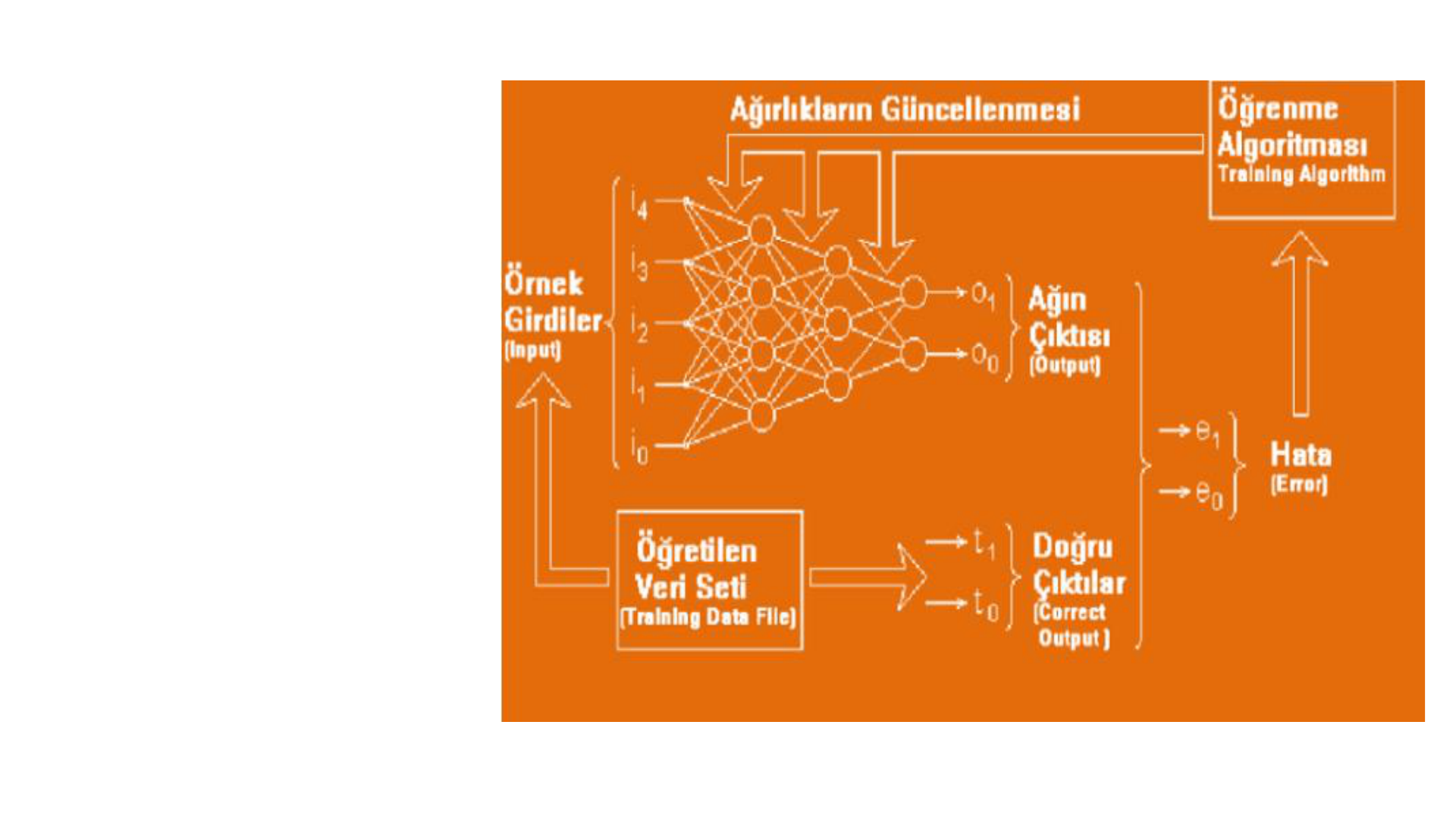
Genelleştirilmiş Delta Öğrenme Kuralı’nın yapısı
Ağın öğrenebilmesi için örnek giriş ve çıkışlardan oluşan eğitim seti şarttır. Geri
Yayılımlı Yapay Sinir Ağları’nda öğrenme işlemi bir anlamda örnek setindeki giriş
değerleriyle, çıkış değerlerini eşleştiren fonksiyonu bulma işlemidir.
Sistemin öğrenme metodu genel olarak iki aşamadan oluşur. Birinci kısım ileri
doğru hesaplamadır. İkinci kısım ise geri doğru hesaplamadır.
İleri doğru hesaplama, aşamasında sisteme verilen girdi ara katmanlardan
geçerek çıkışa ulaşır. Her işlem elemanına gelen girdiler toplanılarak net girdi
hesaplanır. Bu net girdi aktivasyon fonksiyonundan geçirilerek mevcut işlem
elemanının çıktısı bulunur ve bu çıktı değeri bir sonraki katmanda bulunan işlem
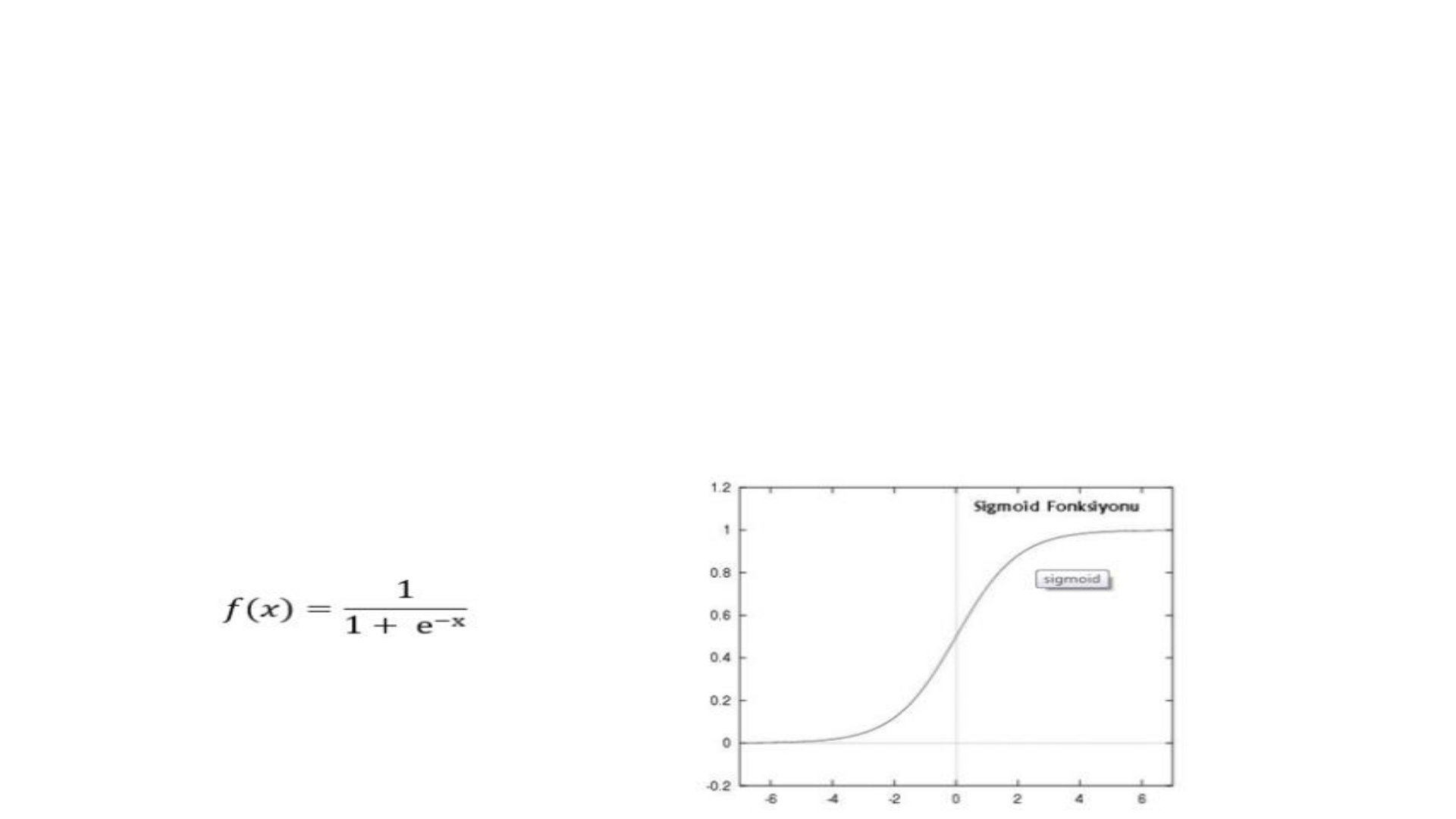
elemanlarına gönderilir. Bu işlemler tekrar edilerek en son çıktı katmanından
çıktılar elde edilir. En çok kullanılan aktivasyon fonksiyonu olan sigmoid
fonksiyonu şekildedir.

Ağdan çıktı alınmasıyla öğrenmenin ilk aşaması bitirilmiş olur.
İkinci aşama hatanın dağıtılması olacaktır. Beklenen çıktı
değeri ile elde ettiğimiz birbirinden farklı ise hata vardır.
Geriye doğru hesaplama aşamasında hata ağırlık değerlerine
dağıtılarak her iterasyonda azaltılması beklenir. Sisteme
başlangıçta random olarak verilen ağırlık değerleri, hataların
ağırlıklara dağıtılmasıyla her iterasyonda güncellenmiş olur.

MLP ile birlikte YSA tarihinde
yeni bir dönem başlamıştır.
Geniş kullanım alanına sahiptir. Örnek verecek olursak;
Otomotiv alanında yol izleme, rehberlik vs. gibi konularda
kullanılmaktadır. Bankacılıkta kredi kartı suçu tespiti ve kredi
uygulamalarında kullanılmaktadır. Uzay sanayinde uçuş
simülasyonu ve otomatik pilot uygulamalarında kullanılır.
Finans sektöründe ise döviz kuru tahminlerinde kullanılır.